ARMv8的内存硬件
关于段页式内存管理,这里不再多说,可直接见x86架构和Linux内存管理那篇,这里只需要再强调一下分页的思想,它是让程序暂时不用的物理内存先放在其他位置(如交换到磁盘),从而显著提高内存可用率,在操作系统中分页和分页器(pager)也就是做这方面事的。本文接下来主要讲相关硬件和内存管理机制。
硬件部分
首先是内存本身,同样包括物理内存和高速缓存,对它们的访问同样使用的是虚拟地址(VA),并由MMU或TLB自动做地址转换获取实际的物理地址(PA),这里面就涉及到很多寄存器,但本文只记录三类控制寄存器:
TTBCR(Translation Table Base Control Register)/TCR(Translation Control Register)
这两类寄存器作用类似,用于控制阶段1虚拟地址到物理地址的转换行为,配置页表大小和地址空间范围,分别对应着AArch32和AArch64两种状态,前者是32位后者为64位,但它们之间可以做映射(TCR_EL1[31:0]->TTBCR TCR_EL1[63:32]->TTBCR2),先看TTBCR如下图:
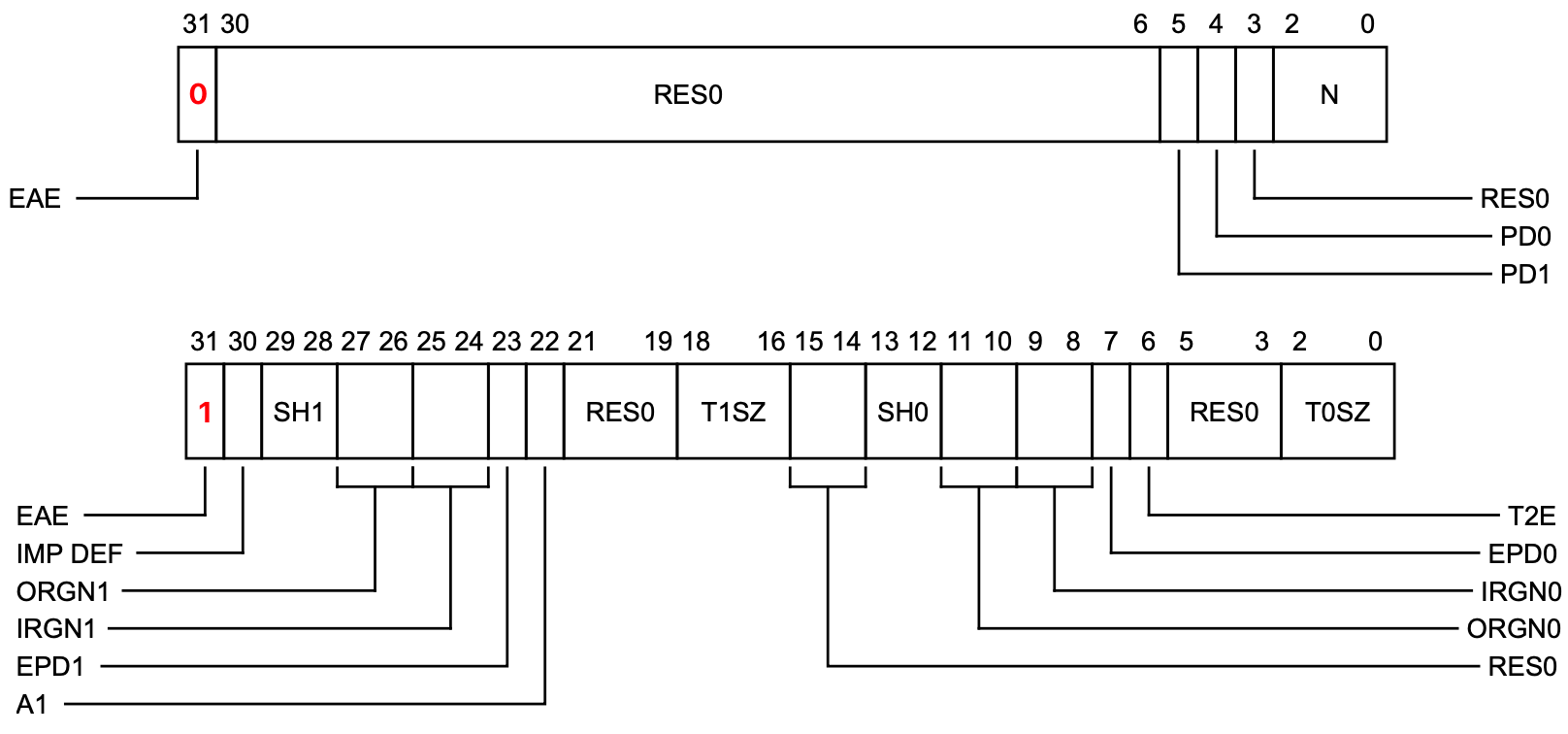
主要关注EAE即Extended Address Enable用于控制地址空间是32位还是64位滴,T2E表示是否激活TTBCR2。现在基本都是ARM64了,通常在AArch64态,armv8存在3个TCR,分别对应EL1~EL3,下面是TCR_EL1各位的定义:
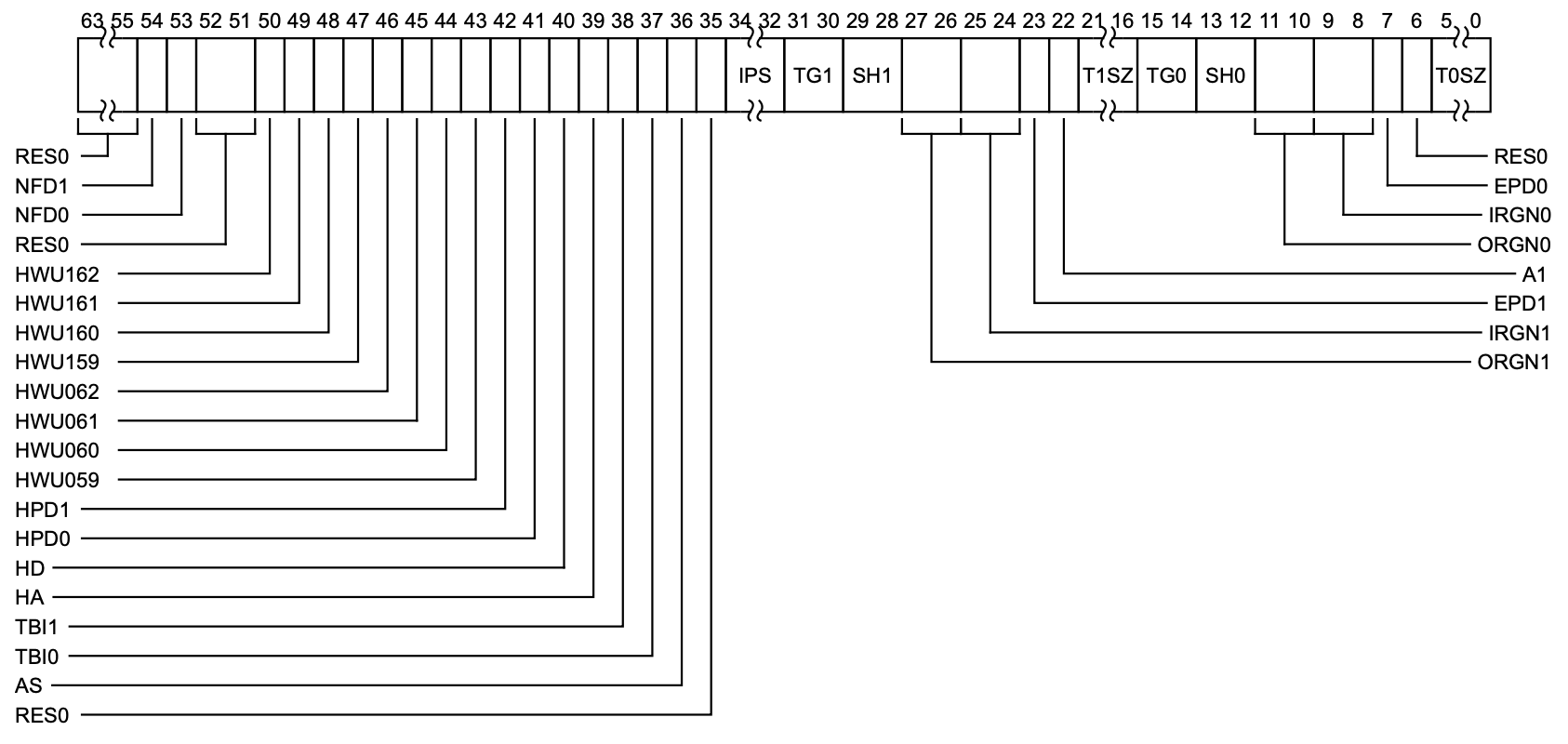
这里主要关注两类,与地址转换相关域和与高速缓存相关的域。图里面有很多xx0和xx1,它们是同种配置项对应的低位(0)区域和高位(1)区域,下面每种只挑一个说明。首先是IPS 它用于配置中间物理地址(Intermediate Physical Address, IPA)的大小:
| IPS 值 | 物理地址大小 | 地址空间范围 | 备注 |
|---|---|---|---|
000 |
32 bits,PA[31:0] | 4 GB | |
001 |
36 bits,PA[35:0] | 64 GB | |
010 |
40 bits,PA[39:0] | 1 TB | |
011 |
42 bits,PA[41:0] | 4 TB | |
100 |
44 bits,PA[43:0] | 16 TB | |
101 |
48 bits,PA[47:0] | 256 TB | 默认值 |
110 |
52 bits,PA[51:0] | 4 PB | 仅支持 ARMv8.2-LPA 且粒度为 64KB |
| 其他值 | 保留 | 行为与 101 相同 |
未来可能改变,软件不应依赖 |
然后是TGn,它用于配置 TTBRn 的页表粒度(Granule Size),即页表的最小单位大小,可取如下值:
| TGn 值 | 粒度大小 | 备注 |
|---|---|---|
01 |
16 KB | |
10 |
4 KB | |
11 |
64 KB | |
| 其他值 | 保留 | 硬件会将其视为实现定义的粒度大小(IMPLEMENTATION DEFINED)。 |
而TnSZ用于配置 TTBRn 所管理的内存区域的大小偏移量,即( 2^{(64 - \text{TnSZ})} ) 字节。接下来是是和高速缓存相关的域,首先是SHn字段用于配置与 TTBRn 相关的页表遍历内存的共享属性:
| SHn 值 | 共享属性 | 备注 |
|---|---|---|
00 |
非共享 | |
10 |
外部共享 | |
11 |
内部共享 | |
| 其他值 | 保留 | 行为是 CONSTRAINED UNPREDICTABLE(受限不可预测)。 |
接下来用ORGNn和IRGNn 字段配置与 TTBRn 相关的页表遍历内存的外部与外部缓存属性:
| O/IRGNn 值 | 外/内部缓存属性 |
|---|---|
00 |
普通内存,外/内部不可缓存 |
01 |
普通内存,外/内部写回、读分配、写分配缓存 |
10 |
普通内存,外/内部写通、读分配、不写分配缓存 |
11 |
普通内存,外/内部写回、读分配、不写分配缓存 |
TTBR (Translation Table Base Register)
TTBR和x86的cr3类似用于指向页表的物理基址,armv8在每个EL有两个TTBR,TTBR0和TTBR1分别指向虚拟地址空间的低区和高区,先看在AArch32(TTBCR.EAE=0)下,各位含义如下:

TTB0是基址,至少对齐到2^7处,剩下几位就是是否共享/内外部共享/共享属性,和TCR的差不多就不多说了。再看看AArch64的,含义如下:

BADDR是基址不多说,主要是ASID(Address Space Identifier,地址空间标识符) 它是 ARM 架构中用于优化 TLB性能的一种机制,它用于标识不同的地址空间(如不同进程的地址空间),每个地址空间都有一个唯一的 ASID,TLB 条目会与 ASID 关联,这样就避免了TLB 刷新,即在上下文切换时(如进程切换),如果没有 ASID,TLB 需要被刷新以避免地址冲突,使用 ASID 后,TLB 可以保留多个地址空间的条目,只需切换 ASID 即可。注意它只有4位或8位,如果用尽了就得全部重置,另外它受TTBCR的A1位控制。
SCTLR (System Control Register)
SCTLR是系统控制寄存器,各位如下:
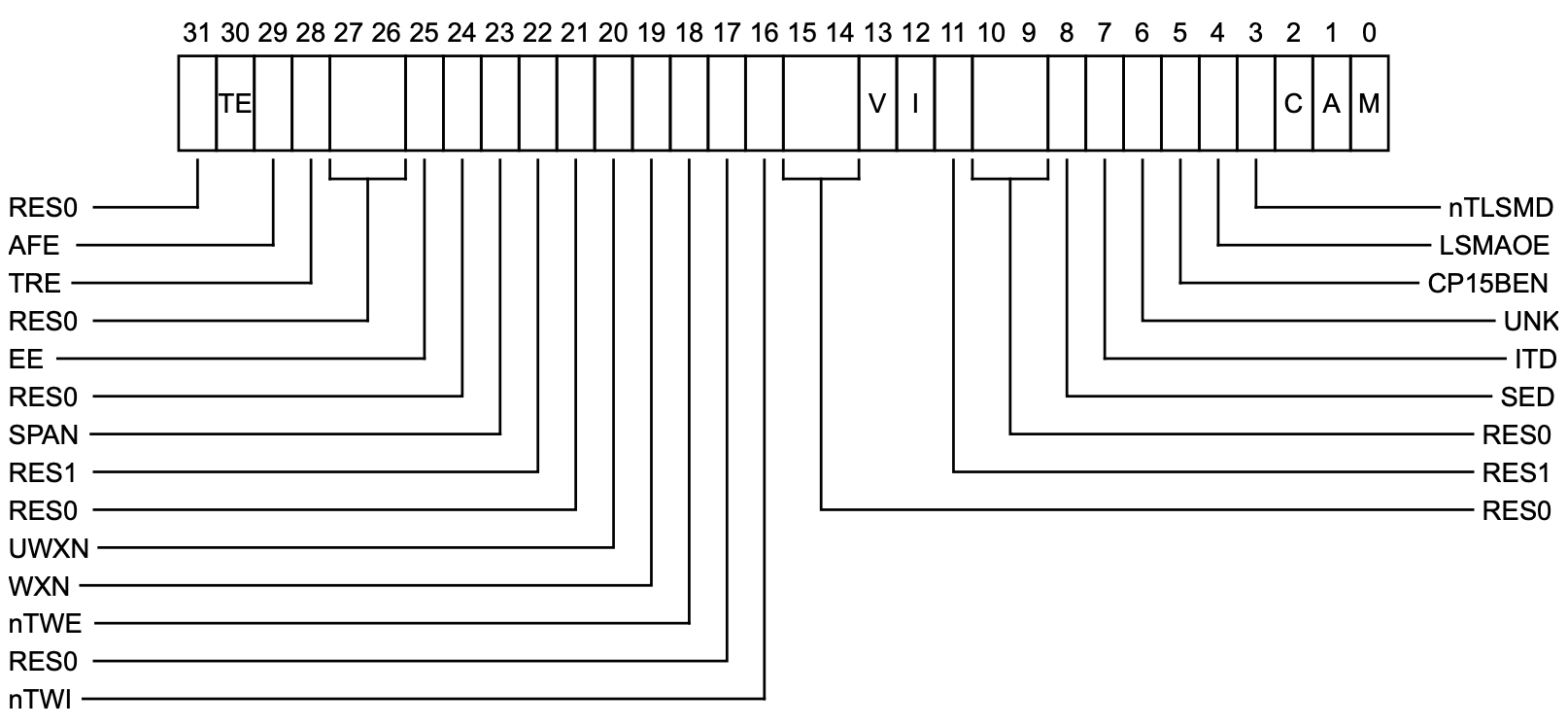
其中有三位和内存管理有关,I位控制 EL1 和 EL0 的指令访问是否可以被缓存,C位控制 EL1 和 EL0 的数据访问是否可以被缓存,M控制 EL1 和 EL0 的阶段 1 地址转换(MMU)是否启用。
注:上面只涉及阶段1的转换,即VA到PA,如果需要使用硬件虚拟化,就涉及二阶转换,自己查手册吧😛~
页表结构
结构总览
接下来描述AArch64下的页表,它支持48位和52位(ARMv8.2-LVA扩展)地址宽度,这里以48为例,上面已经提到这48位空间可以被划分为两个区域(双VA范围),低区(用户区)与高区(内核区):
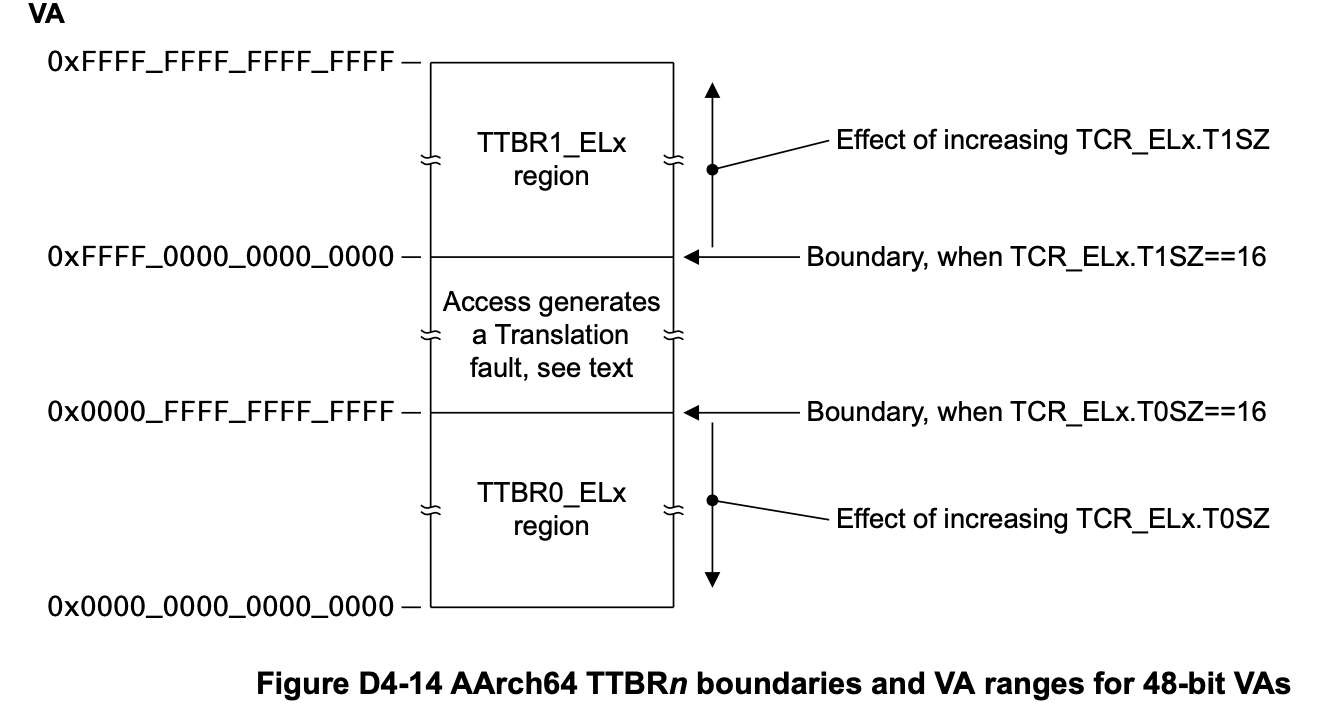
当然也可以只有一个区(低区)咯,暂且不表。它支持4K,16K,64K共3种页面粒度,如下图:
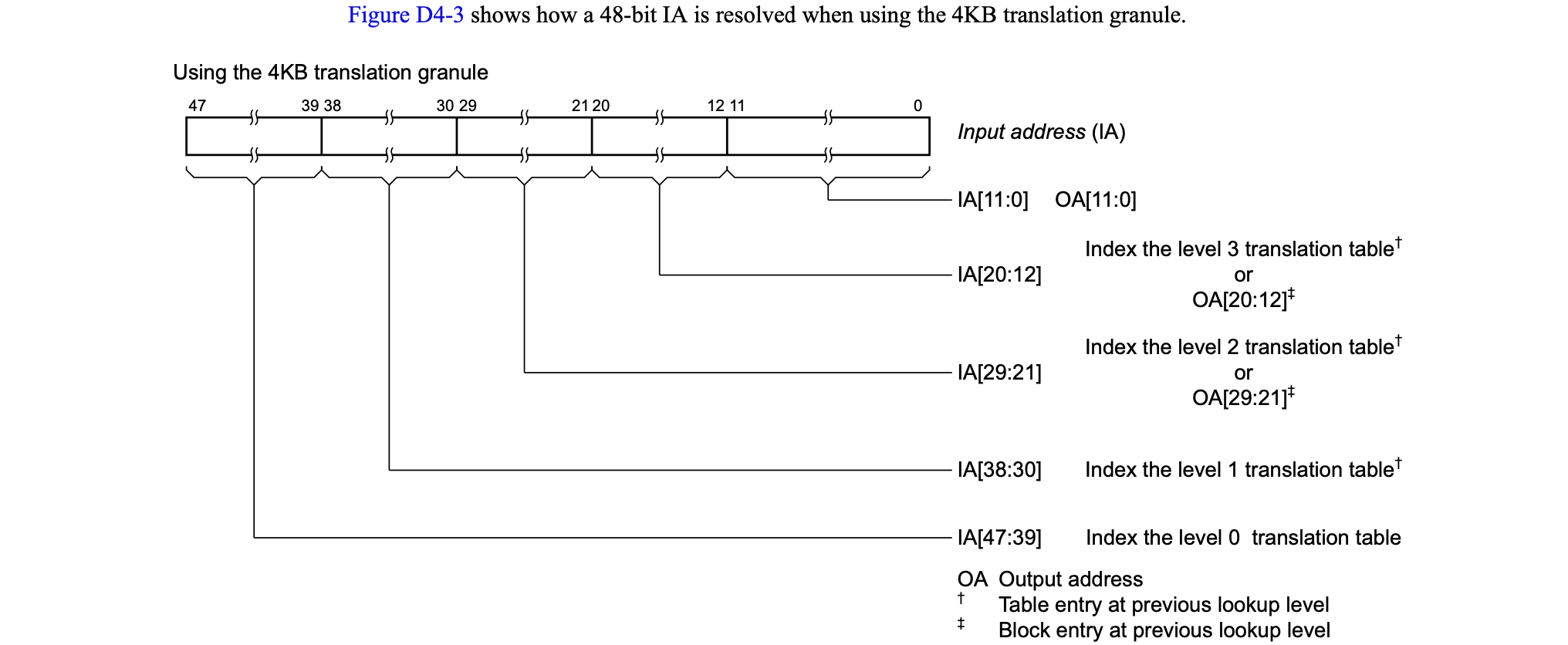
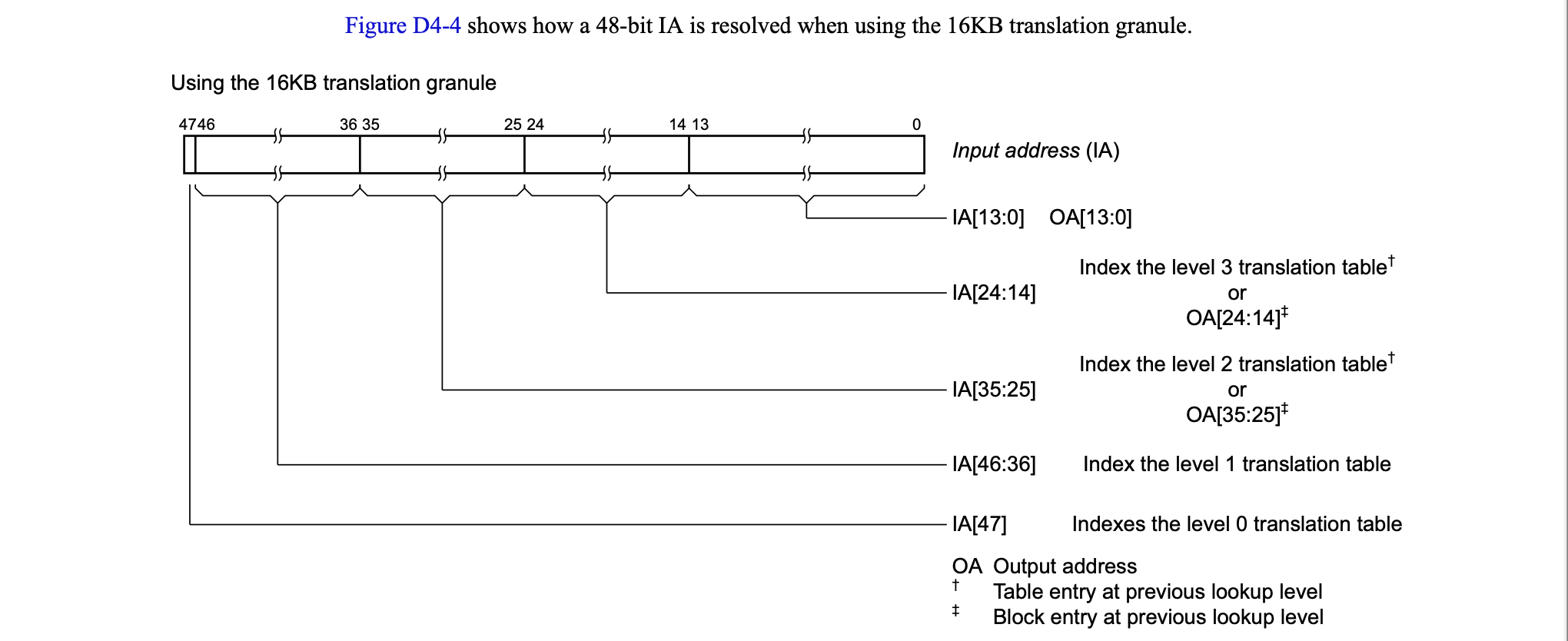
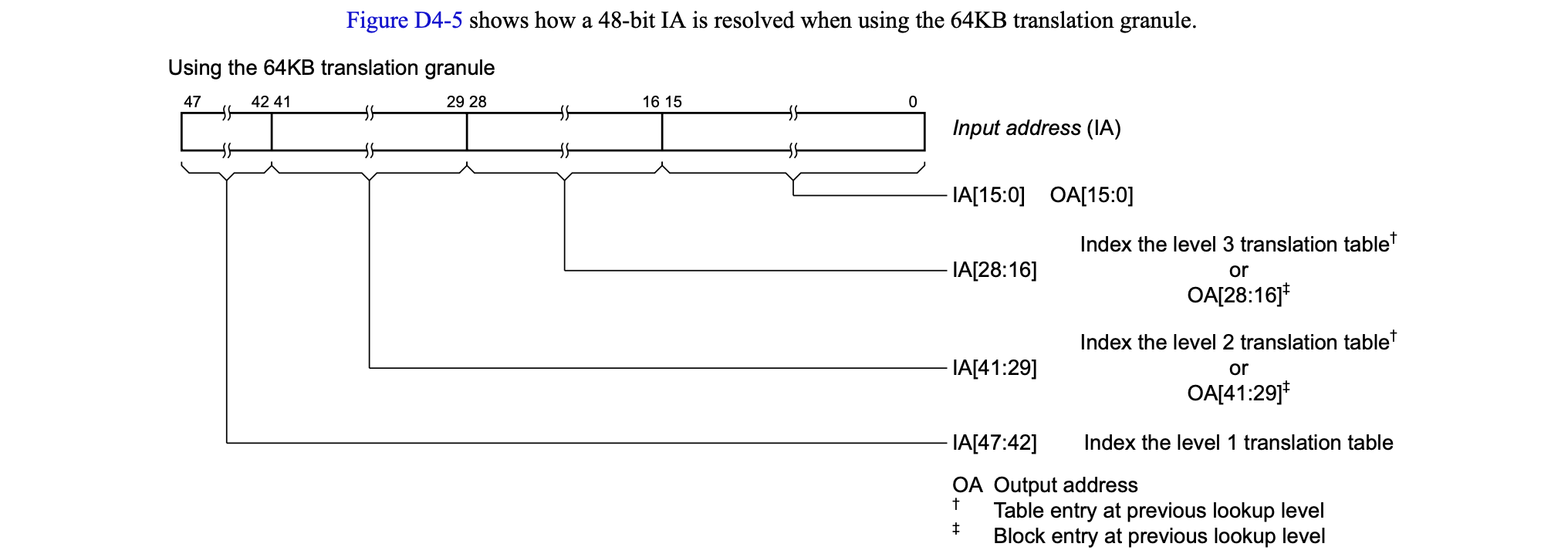
除此外它支持最多4级页表映射,以4K粒度的页表为例,如下图:
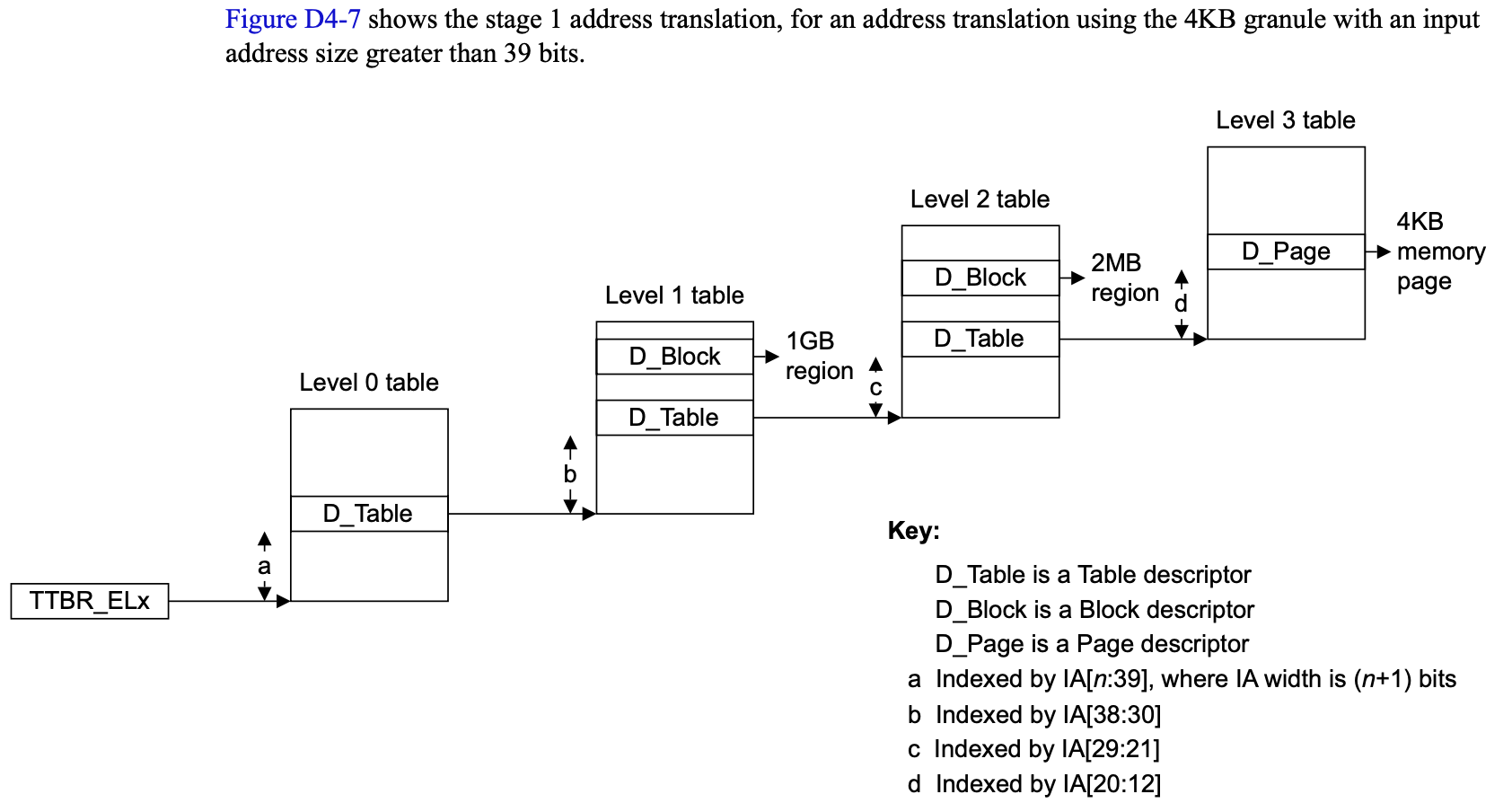
注意看这里面它有Block,Table,Page三种类型,它是指每级页表都可能存下级页表或是直接指向一个大块的区域首地址,下面会详细说明。
页表项描述符
页表最多分4级,其中L0~L2内容差不多,如下图根据最低两位表示3种情况:
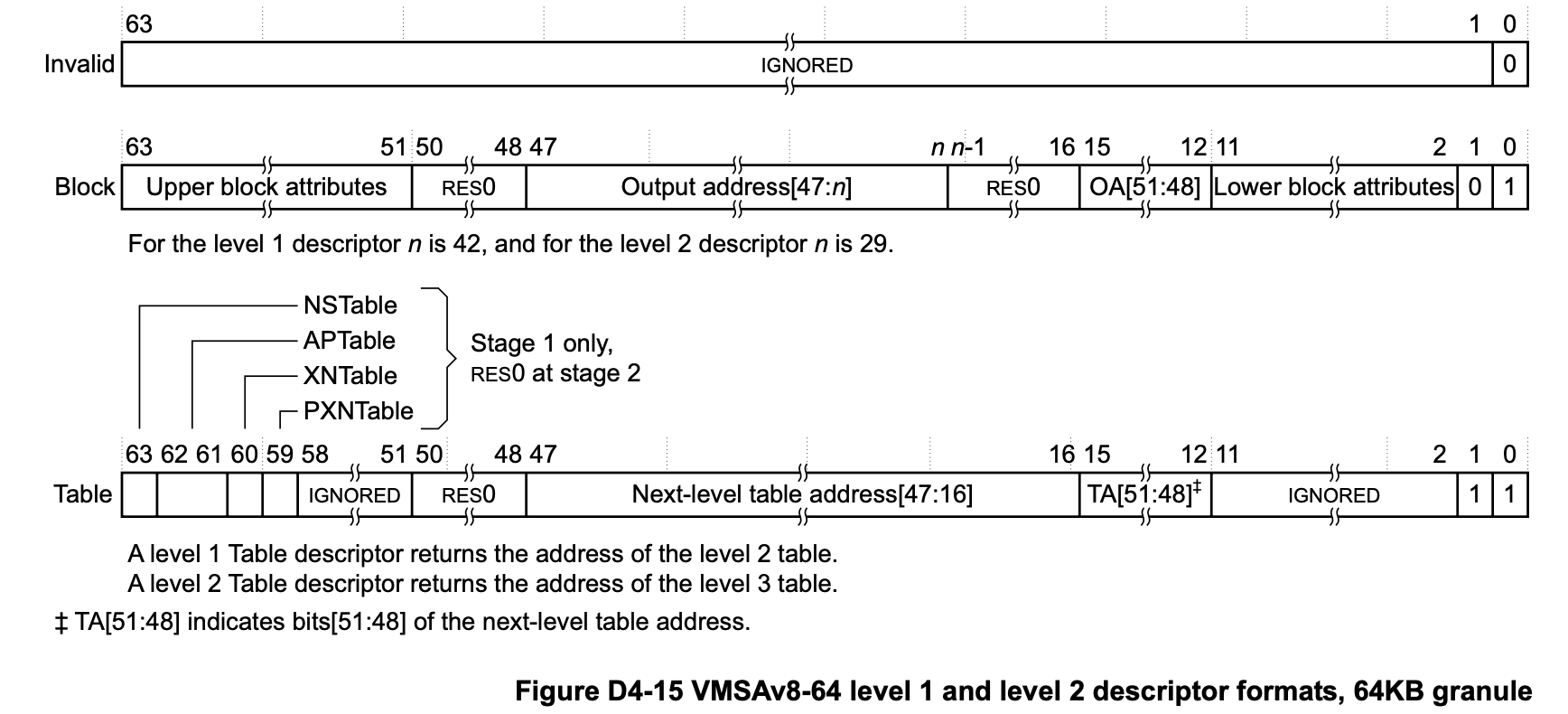
bit[0]指示该项是否有效,bit[1]表明是指向一个Block物理地址(0)还是指向下一级的基址(1)。再看L3,如下图它存在5种情况:

bit[0]表示是否有效,bit[1]表示是否是保留,若为0和bit[0]=0差不多,剩下的就是存最终的物理地址的三种类型。除了地址,这里面还有表和页的属性,下面详细说明每个域的含义,首先是页表的属性:
| 属性 | 位域 | 描述 | 种类 |
|---|---|---|---|
| NSTable | bit[63] |
|
|
| APTable | bits[62:61] |
|
|
| UXNTable/XNTable | bit[60] |
|
|
| PXNTable | bit[59] |
|
|
接下来是内存页属性:
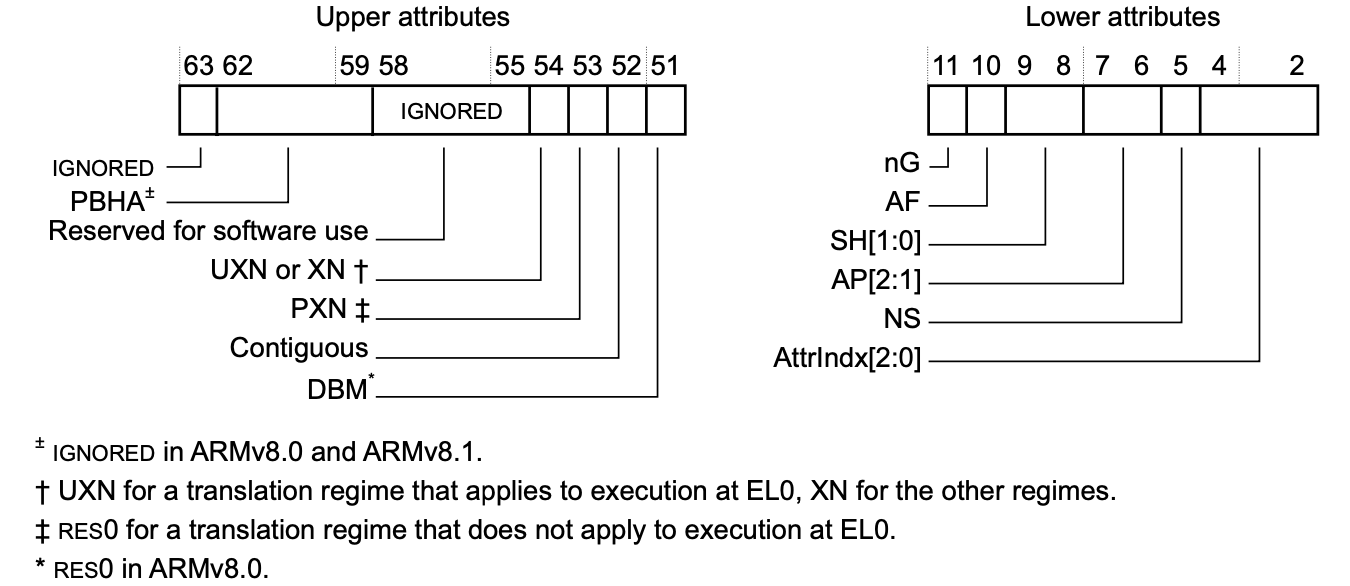
| 字段 | 描述 | 种类及含义 |
|---|---|---|
| PBHA (bits[62:59]) |
|
|
| UXN 或 XN (bit[54]) |
|
|
| PXN (bit[53]) |
|
|
| Contiguous (bit[52]) |
|
|
| DBM (bit[51]) |
|
|
| nG (bit[11]) |
|
|
| AF (bit[10]) |
|
|
| SH (bits[9:8]) |
|
|
| AP[2:1] (bits[7:6]) |
|
|
| NS (bit[5]) |
|
|
| AttrIndx[2:0] (bits[4:2]) |
|
|
这里再介绍下最后的属性索引字段,它是指示这段内存是普通内存还是设备内存以及含有什么属性,具体属性是存在MAIR寄存器中,它是64位的,并使用8位来表示一种属性,可能属性有:
| Bit[7:4] | Bit[3:0] | 说明 |
|---|---|---|
| 0000 | 0000 | Device-nGnRnE 内存,G表示是否聚合,即把连续的多个小访问优化为一次的大访问 |
| 0000 | 0100 | Device-nGnRE 内存,R表示是否重排,即访问请求必须按照程序顺序执行。 |
| 0000 | 1000 | Device-nGRE 内存,E表示是否提前应答,即写操作必须等到数据真正写入内存后才能确认完成。 |
| 0000 | 1100 | Device-GRE 内存 |
| 0000 | 0011 | 未定义 |
| 0011 | 0011 | 普通内存,写直通策略(短暂性) |
| 0100 | 0100 | 普通内存,关闭高速缓存 |
| 0111 | 0111 | 普通内存,回写策略(短暂性) |
| 1011 | 1011 | 普通内存,写直通策略 |
| 1111 | 1111 | 普通内存,回写策略 |
注:上文的RES0是保留为0的意思哦~
安全增强
| 安全特性 | 英文拼写 | 说明 | 应对的攻击 | 体系架构 |
|---|---|---|---|---|
| XN | Execute Never | 不可执行。一般用于配置数据段不可执行,防止数据段注入可执行的shellcode,使用XN可执行DEP(Data Execute Prevention,通常说的堆栈不可执行)。 | 任意地址读写、代码段覆盖 | v8以及以前 |
| PXN | Privileged Execute Never | 特权模式不可执行。防止在内核态模式下直接跳转到用户态的代码段进行提权攻击。 | 执行流导向用户空间 | v8以及以前 |
| XOM | Execute Only Memory | 内存只可执行,不可读。防止执行逻辑泄露。 | 信息泄露 | v8.1/2 |
| WXN | Write Execute Never | 可写的内存不可执行。防止注入的shellcode可被执行。 | 任意地址读写 | v8.1/2 |
| PAN | Privileged Access Never | 两者配合使用,实现内核态不允许访问用户态应用的数据的效果。防止高权限的内核偷应用的数据。 | 数据流导向用户空间 | v8.1/2 |
| UAO | User Access Only | 用户态访问限制。防止内核态访问用户态数据。 | 数据流导向用户空间 | v8.1/2 |
| PA | Pointer Authentication | 函数指针检查,CPU在执行函数跳转时检查函数指针是否正确(使用MAC算法),防止跳转指针被修改。 | ROP/JOP攻击 | v8.3 |
| BTI | Branch Target Identifiers | 对间接跳转的目标进行限制。与PA结合使用极大程度减少控制流攻击。 | JOP攻击 | v8.5 |
| MT | Memory Tagging | 内存区域进行标记,对保护区域访问必须使用具有相同标记的指针。可检测溢出、UAF类漏洞。 | 防溢出、UAF | v8.5 |
| ASLR | Address Space Layout Randomization | 内存地址随机化。基于MMU实现,对于应用来说,每次动态加载时,起始地址不同,增加攻击难度,增加对特定地址植入代码的难度。 | 特定地址定位 | v8以及以前 |
| CFI | Control Flow Integrity | 控制流完整性。防止ROP攻击。 | ROP/JOP攻击 | N |
这里重点介绍几个:
PAC
这是动态分析*OS经常要处理的东西,从原理看,ARM64的虚拟地址只用了低48/52bit,PAC就利用剩余的高位存储签名:
64-bit 指针布局(PAC 启用后):
bit63 bit48 bit47 bit0
┌────────────────┬──────────────────────┐
│ PAC 签名 │ 实际地址 │
│ (~8 bit) │ (虚拟地址低位) │
└────────────────┴──────────────────────┘
签名计算:
PAC = QARMA( ← 轻量级密码学算法,1~2个周期内完成计算
key, ← CPU内部密钥,软件不可读
pointer, ← 被签名的指针值
context ← 上下文数据(通常是栈指针SP)
)
arm64e通过提供额外的寄存器和指令来实现它,首先是for key,它定义了5类密钥:APIAKey/APIBKey是保护指令指针的,APDAKey/APDBKey是保护数据指针的,还有一个通用密钥APGKey,不同的任务拥有不同的key且无法被读取从而保证key的安全性。然后是指令,含三类,PAC为签名,AUT为验证,XPAC为去掉保护,例如:
签名指令(Sign):
PACIA Xn, Xm 用IA密钥签名Xn,context=Xm
PACIBSP 用IB密钥签名LR,context=SP
验证+使用指令(Authenticate):
AUTIA Xn, Xm 验证并去除PAC,context = Xm
剥离:
XPACI Xn 直接去掉签名,不做任何校验
组合指令(常用):
RETAA = AUTIA + RET(验证返回地址后返回)
BLRAAZ Xn = AUTIA + BLR(验证后间接调用)
BRAAZ Xn = AUTIA + BR(验证后间接跳转)
PAC保证在跳转前,需要认证的指针是正确的,但是可能存在一些没有被保护的跳转指令,或者找到了一个带合法签名但可以被利用的指针,所以后来又出现了BTI。
BTI
和PAC互补,它是保证跳转的目标地址是合法的,即不管从哪里怎么跳转来,但只能跳转到合法的入口开始执行,比如很多JOP/ROP会跳转到函数中间开始,此时若激活了BTI将会出现Branch Target Exception。为了支持BTI,arm64在页表项(PTE)上田姐了Guarded Page(PG)标识位,若存在该标记,那么通过间接跳转进该页的目标地址必须是BTI指令,而且存在三个变体:
1.BTI c:只允许BLR跳进来(Function Call)
2.BTI j:只允许BR跳进来(如switch分支)
3.BTI jc:同时允许BR会BLR
在它之后就可以是原来的正常指令了。
Apple的内存安全增强
KIP
KIP(Kernel Integrity Protection)主要是防止内核及驱动程序代码在运行时被修改,它靠一个专有硬件,Memory Controller,它能在启动完成后被锁定,在锁定后会拒绝任何对受保护无力内存区域的写入请求,并且只有通过芯片重置(重启)才能接触锁定,它是一种比接下来要讲的PPL还强力的保护手段。
PPL
在内核漏洞利用中,修改页表是一个重要的操作,页表本身存放在内存中所以难以用页表保护页表,Apple为此设计很多专有硬件,并在这些硬件上实现了多种页表保护机制,首先就是本节要说的PPL(Page Protection Layer),它其实依赖新的专有硬件,如可视的64位APRR(Access Permissions Remapping Register)寄存器,简单来说它在页表项到真实权限之间再加了一层,原来只需要页表的AP[1] AP[0] UXN PXN用来表示rwx权限,现在它引入了快速权限限制(FPR)技术,页表上这4bit只是索引,处理器会用它去查APRR,APRR对应位存储真正可用的权限,如下图(没找到APRR的图,这里用下文要讲的SPRR代替,它们两个很像!):
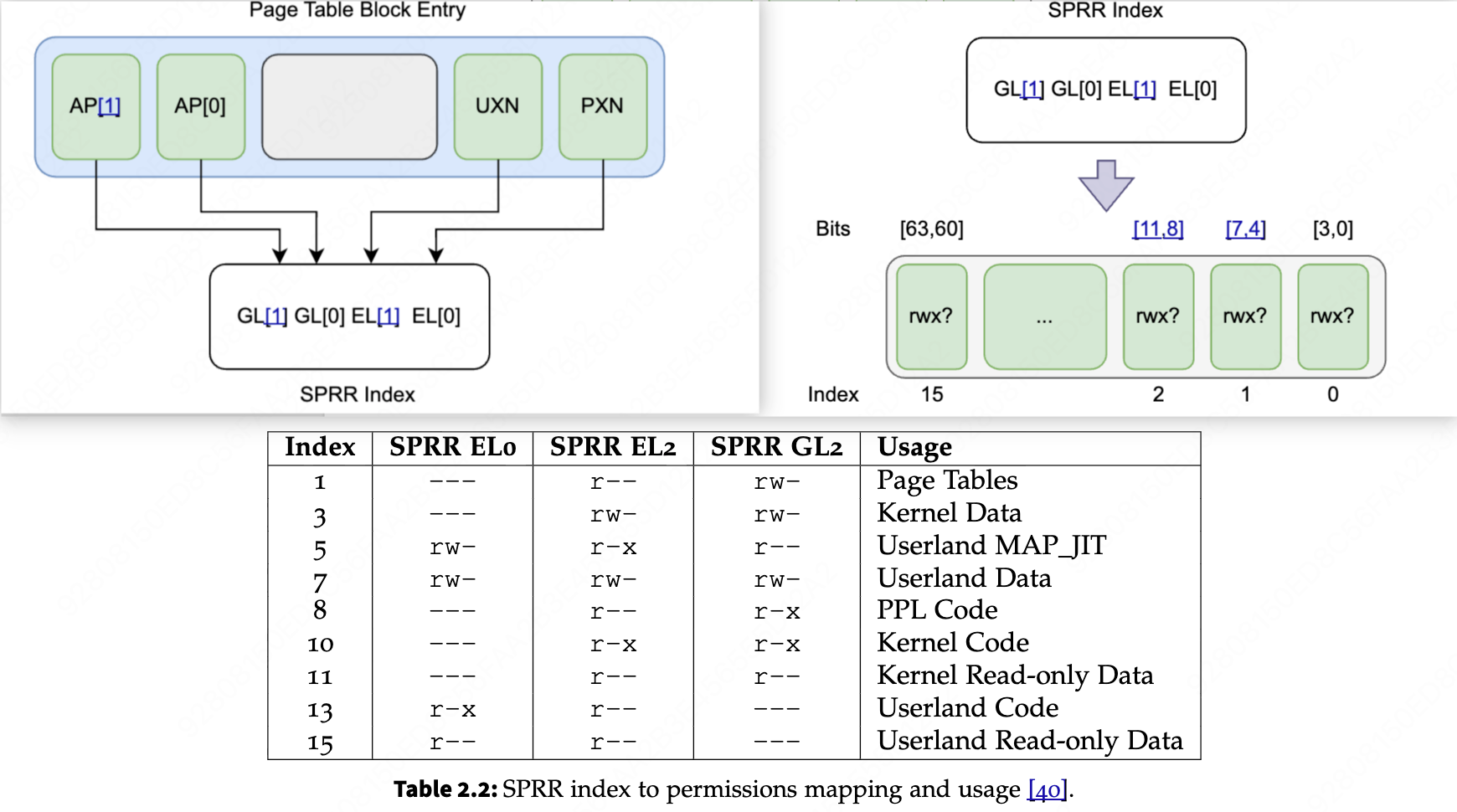
利用它即可实现不修改页表来重新映射内存区域的权限,但在此处它和页表一起可实现相互保护,具体来说现在页表会被只读映射,当内核需要修改页表时,会通过特殊的蹦床(__PPLTRAMP)段进入PPL代码来实现,PPL代码也是只读的,PPL会临时修改APRR来使页表区域的权限位可写,然后修改页表区域,在离开PPL前会恢复APRR使页表区域重新变为只读,通过此来收缩页表修改能力,减少攻击面。
SPTM
安全页表监视器是PPL的替代者,它在传统的Exception Level旁边引入了新的Guarded Level,GL有三个级别,SPTM运行在最高特权GL2上,它取代了PPL成为系统中管理内存重映射和页表操作的唯一组件,而且它不止有内存管理能力,它还引入了TXM去取代AMFI的部分能力,引入SK去充当Exclaves生态的微内核,这些将会在后续的安全专题中仔细介绍,下面这节放一张架构图:
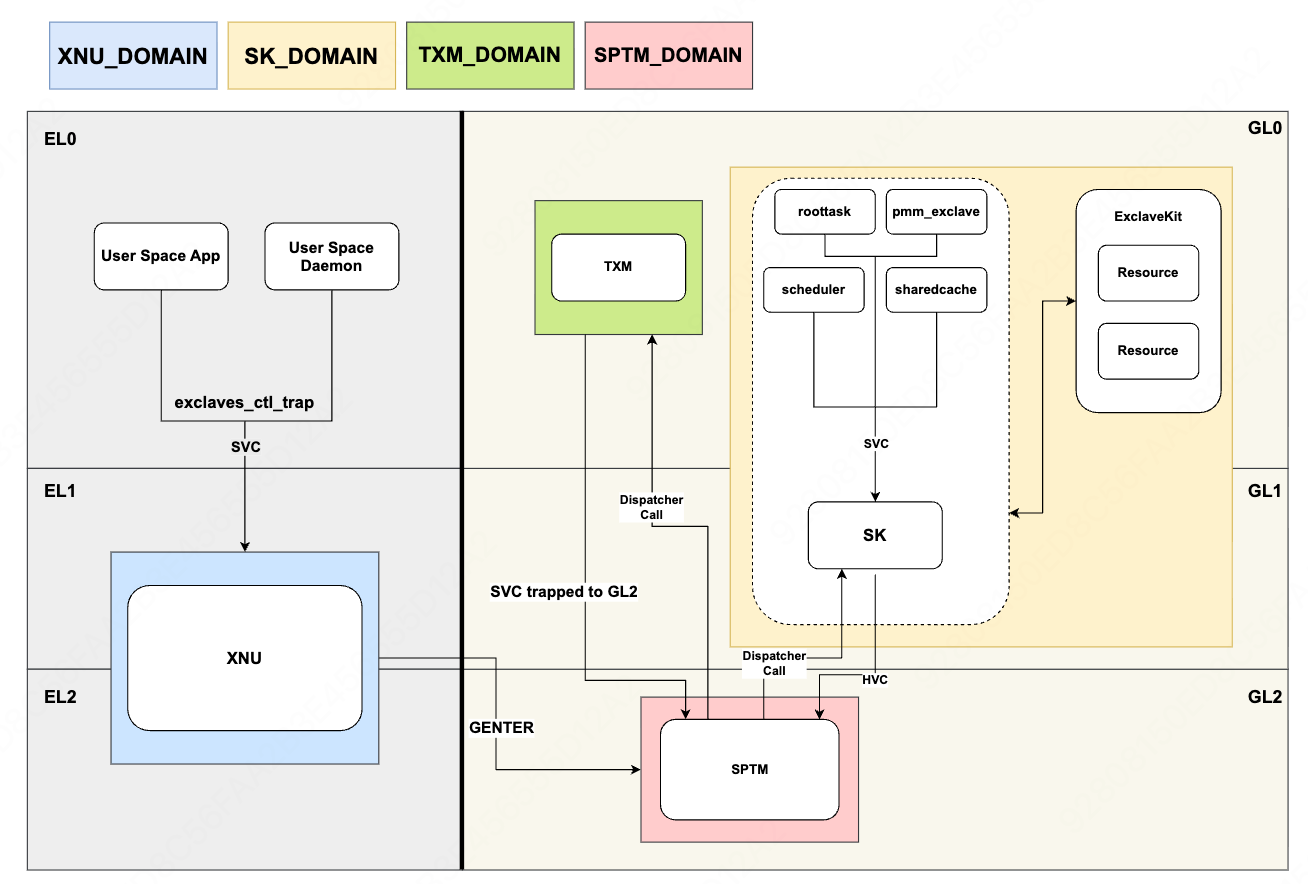
EL1/EL2可使用GENTER进入SPTM,SPTM根据x16的高位决定是执行SPTM操作,还是分发到TXM(GL0)/SK(GL1),在GL0或GL1可通过SVC/HVC回到GL2,而GL2通过GEXIT回到EL1/EL2里,这部分在签名那章会再仔细介绍,这里可以先做了解~
MACH虚拟内存机制
MACH设计为微内核,在内存子系统上分为两层,上层虚拟内存是架构无关的,而底层物理内存是机器相关但会暴露一个不透明接口,在这个子系统中定义了很多关键结构,看懂它们就能理解它的内存管理机制了。
关键结构
总览
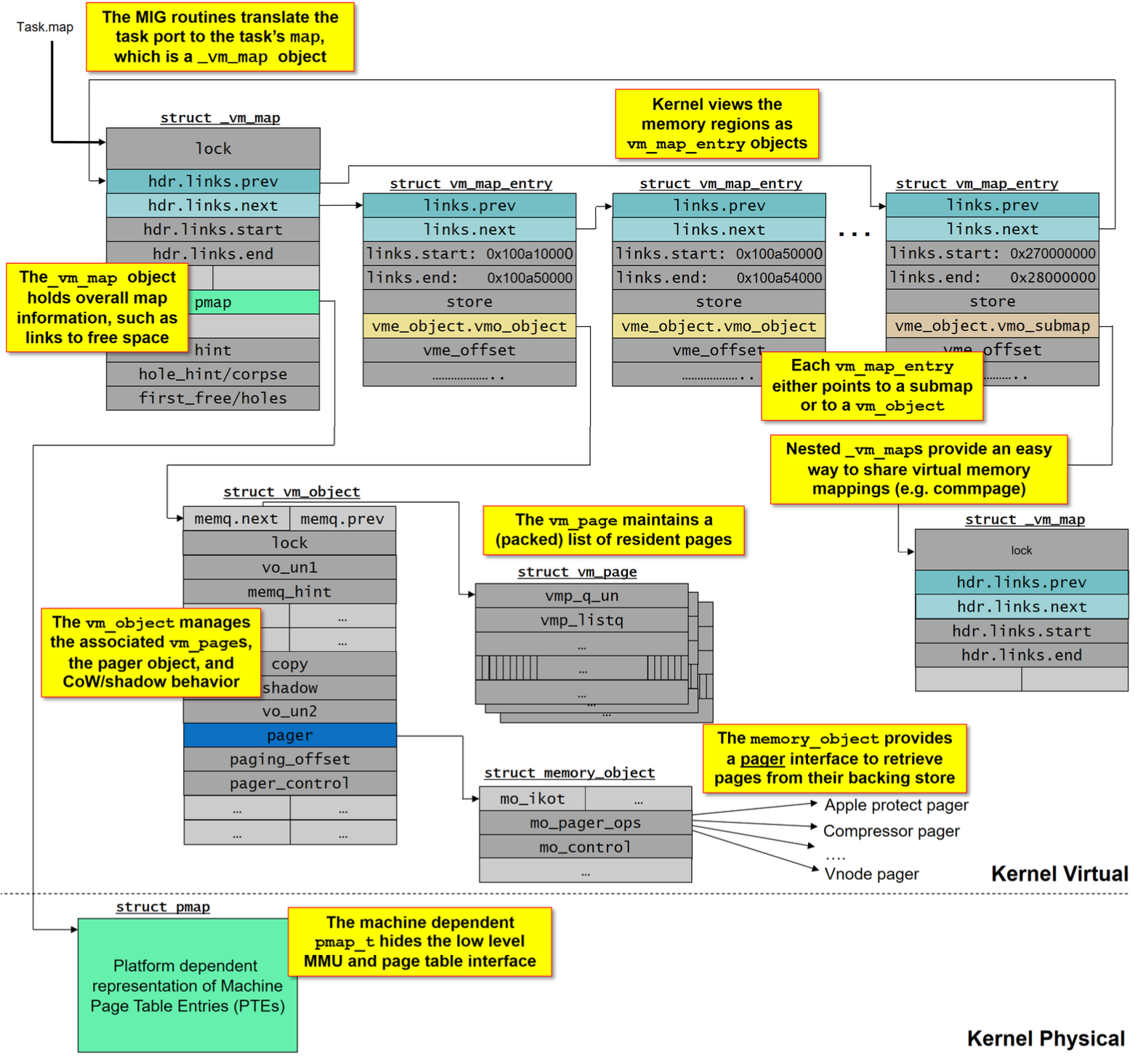
首先从这个关系图,这里先简单描述下各结构用途:
- _vm_map:进程的虚拟内存由
_vm_map结构管理,可能有两个该结构分别管理用户和内核区域的内存,它也是很多内存管理函数起点,比如它链接着vm_map_entry和pmap,分别表示一个个内存区域和实际的物理内存。 - vm_map_entry:
vm_map_entry表示一个个连续的内存区域,它可以指向vm_object来表示实际的内存分配信息,也可以指向子映射vm_map_entry,这种分层方式便于内存组织与管理。 - vm_object:链接着实际的虚拟地址页信息,所有分配的虚拟地址最终都会存在这个结构里,它也通过
shadow去链接之前的块来实现高效的拷贝行为,使用pager去指向分页器结构实现分页行为。 - vm_page:它用于管理物理页面的信息,被分配在
vm_page_array数组中,大体和物理页面数对应。 - memory_object:它是一个分页器接口,可以在它上面进行实现与扩展来实现各类分页器,比如普通的swap,加密段加载等。
- vm_map_copy:这是一个临时结构,用来表示一个内存复制的中间态,这有利于实现跨进程/用户态的内存复制。
- pmap:它负责将虚拟内存映射到物理内存,它通过操作页表(Page Table)来实现虚拟地址到物理地址的转换。
- upl:通用页面列表(Universal Page List)的简称,它用于统一于虚拟内存系统通信,包括改变页面在缓存/权限/映射等方面的行为,也用于分页操作(将数据从内存中换出/换入)。
_vm_map
它的定义与解释如下:
struct vm_map_links {
struct vm_map_entry *prev; /* 指向前一个虚拟内存映射条目 */
struct vm_map_entry *next; /* 指向下一个虚拟内存映射条目 */
vm_map_offset_t start; /* 当前映射的起始地址 */
vm_map_offset_t end; /* 当前映射的结束地址 */
};
struct vm_map_header {
struct vm_map_links links; /* 虚拟内存映射条目的链表头,包含第一个、最后一个、最小与最大地址 */
int nentries; /* 当前映射中的条目数量 */
uint16_t page_shift; /* 页面大小的位移量(用于计算页面大小) */
uint16_t entries_pageable : 1; /* 标志位,表示映射条目是否可分页 */
uint16_t __padding : 15; /* 填充位,确保结构体对齐 */
#ifdef VM_MAP_STORE_USE_RB
struct rb_head rb_head_store; /* 红黑树的头,用于存储映射条目(如果启用了红黑树存储) */
#endif /* VM_MAP_STORE_USE_RB */
};
struct _vm_map {
lck_rw_t lock; /* 读写锁,用于保护映射的并发访问 */
struct vm_map_header hdr; /* 映射条目的头部信息 */
#define min_offset hdr.links.start /* 映射范围的最小地址 */
#define max_offset hdr.links.end /* 映射范围的最大地址 */
pmap_t XNU_PTRAUTH_SIGNED_PTR("_vm_map.pmap") pmap; /* 物理内存映射 */
vm_map_size_t size; /* 虚拟内存映射的总大小 */
uint64_t size_limit; /* 地址空间大小的限制 */
uint64_t data_limit; /* 数据大小的限制 */
vm_map_size_t user_wire_limit;/* 用户锁定内存的限制,wire即为不能分页换出 */
vm_map_size_t user_wire_size; /* 当前用户锁定内存的大小 */
#if __x86_64__
vm_map_offset_t vmmap_high_start; /* 高地址空间的起始地址(仅用于 x86_64 架构) */
#endif /* __x86_64__ */
os_ref_atomic_t map_refcnt; /* 引用计数,用于管理映射的生命周期 */
#if CONFIG_MAP_RANGES
#define VM_MAP_EXTRA_RANGES_MAX 1024
struct mach_vm_range default_range; /* 默认的虚拟内存范围 */
struct mach_vm_range data_range; /* 数据段的虚拟内存范围 */
uint16_t extra_ranges_count; /* 额外的虚拟内存范围数量 */
vm_map_user_range_t extra_ranges; /* 额外的虚拟内存范围 */
#endif /* CONFIG_MAP_RANGES */
union {
vm_map_offset_t vmu1_highest_entry_end; /* 最高分配的映射条目的结束地址 */
vm_map_offset_t vmu1_lowest_unnestable_start; /* 嵌套映射中最低不可解嵌套的起始地址 */
} vmu1;
#define highest_entry_end vmu1.vmu1_highest_entry_end
#define lowest_unnestable_start vmu1.vmu1_lowest_unnestable_start
vm_map_entry_t hint; /* 用于快速查找的提示,去查找可用的一片虚拟地址空间 */
union {
struct vm_map_links* vmmap_hole_hint; /* 用于快速查找空闲区域的提示 */
struct vm_map_corpse_footprint_header *vmmap_corpse_footprint; /* 用于诊断的 corpse 内存映射 */
} vmmap_u_1;
#define hole_hint vmmap_u_1.vmmap_hole_hint
#define vmmap_corpse_footprint vmmap_u_1.vmmap_corpse_footprint
union {
vm_map_entry_t _first_free; /* 第一个空闲空间的提示 */
struct vm_map_links* _holes; /* 所有空闲区域的链表 */
} f_s; /* 空闲空间数据结构的联合体 */
#define first_free f_s._first_free
#define holes_list f_s._holes
unsigned int
/* boolean_t */ wait_for_space:1, /* 调用者是否应该等待空间 */
/* boolean_t */ wiring_required:1, /* 所有内存是否需要被锁定 */
/* boolean_t */ no_zero_fill:1, /* 是否禁止零填充缺失的页面 */
/* boolean_t */ mapped_in_other_pmaps:1, /* 该子映射是否被映射到使用不同物理映射的映射中 */
/* boolean_t */ switch_protect:1, /* 在切换时保护映射免受写错误 */
/* boolean_t */ disable_vmentry_reuse:1, /* 是否禁止重用虚拟内存条目 */
/* boolean_t */ map_disallow_data_exec:1, /* 是否禁止从数据页面执行代码 */
/* boolean_t */ holelistenabled:1,
/* boolean_t */ is_nested_map:1,
/* boolean_t */ map_disallow_new_exec:1, /* 是否禁止新的可执行代码 */
/* boolean_t */ jit_entry_exists:1,
/* boolean_t */ has_corpse_footprint:1,
/* boolean_t */ terminated:1,
/* boolean_t */ is_alien:1, /* 用于平台模拟,例如在 macOS 上模拟 iOS */
/* boolean_t */ cs_enforcement:1, /* 代码签名强制执行 */
/* boolean_t */ cs_debugged:1, /* 代码签名但允许调试 */
/* boolean_t */ reserved_regions:1, /* 是否有保留区域 */
/* boolean_t */ single_jit:1, /* 是否只允许一个 JIT 映射 */
/* boolean_t */ never_faults:1, /* 该映射是否永远不会引发错误 */
/* boolean_t */ uses_user_ranges:1, /* 是否使用用户虚拟内存范围 */
/* boolean_t */ tpro_enforcement:1, /* 是否强制执行 TPRO 传播 */
/* boolean_t */ corpse_source:1, /* 该映射是否用于创建诊断用的 corpse */
/* reserved */ res0:1,
/* reserved */pad:9;
unsigned int timestamp; /* 版本号,用于检测映射的更改 */
};
可见最重要的还是指向的vm_map_entry和pmap。一个任务可能有一个task_map和一个kernel_map,前者是私有的后者是共享的,系统使用它们两个来管理任务所有的虚拟地址分配,即出现内存访问异常时,会根据地址范围以它们为入口开始查找内存分配信息,再看怎么处理,恢复还是终止任务。另外系统中还存在许多其他的_vm_map,它们被用于管理各种特定用途的内存,和这里提到的两个很不一样不要搞混咯。
pmap
如上所诉,就是管理MMU的,主要是指向根页表的,即在建立实际映射时需要根据它去修改底层页表:
struct pmap {
tt_entry_t *tte; /* 指向根页表(Translation Table Entry)的指针 */
pmap_paddr_t ttep; /* 根页表的物理地址 */
vm_map_address_t min; /* 最低可寻址的虚拟地址(包含) */
vm_map_address_t max; /* 最高可寻址的虚拟地址(不包含) */
#if ARM_PARAMETERIZED_PMAP
const struct page_table_attr * pmap_pt_attr; /* 页表布局的详细信息 */
#endif /* ARM_PARAMETERIZED_PMAP */
ledger_t ledger; /* 用于跟踪物理内存映射的分类账 */
decl_lck_rw_data(, rwlock); /* 读写锁,用于保护 pmap 的并发访问 */
queue_chain_t pmaps; /* 全局 pmap 链表 */
tt_entry_t *tt_entry_free; /* 空闲的页表条目链表 */
struct pmap *nested_pmap; /* 指向嵌套(共享)区域的 pmap */
vm_map_address_t nested_region_addr; /* 嵌套区域的起始地址 */
vm_map_offset_t nested_region_size; /* 嵌套区域的大小 */
vm_map_offset_t nested_region_true_start; /* 嵌套区域的真实起始地址 */
vm_map_offset_t nested_region_true_end; /* 嵌套区域的真实结束地址 */
bitmap_t *nested_region_unnested_table_bitmap; /* 嵌套区域的未嵌套表位图 */
_Atomic int32_t ref_count; /* pmap 的引用计数 */
uint32_t nested_no_bounds_refcnt; /* 未设置边界的嵌套 pmap 的数量 */
uint16_t asid; /* 地址空间标识符(ASID)或虚拟机标识符(VMID),0为内核保留 */
#if MACH_ASSERT
int pmap_pid; /* 进程 ID(仅在调试模式下使用) */
char pmap_procname[17]; /* 进程名称(仅在调试模式下使用) */
#endif /* MACH_ASSERT */
bool reserved0; /* 保留字段 */
bool pmap_vm_map_cs_enforced; /* 是否启用了代码签名强制 */
bool reserved1; /* 保留字段 */
unsigned int reserved2; /* 保留字段 */
unsigned int reserved3; /* 保留字段 */
#if defined(CONFIG_ROSETTA)
bool is_rosetta; /* 是否用于 Rosetta 模拟 */
#else
bool reserved4; /* 保留字段 */
#endif /* defined(CONFIG_ROSETTA) */
#if DEVELOPMENT || DEBUG
bool footprint_suspended; /* 是否暂停了内存占用跟踪 */
bool footprint_was_suspended; /* 内存占用跟踪是否曾经被暂停 */
#endif /* DEVELOPMENT || DEBUG */
bool nx_enabled; /* 是否启用了不可执行(NX)功能 */
bool is_64bit; /* 是否表示 64 位地址空间 */
bool nested_has_no_bounds_ref; /* 是否在没有设置边界的情况下嵌套了 pmap */
bool nested_bounds_set; /* 嵌套边界是否已设置 */
#if HAS_APPLE_PAC
bool disable_jop; /* 是否禁用了跳转导向编程(JOP)保护 */
#else
bool reserved5; /* 保留字段 */
#endif /* HAS_APPLE_PAC */
bool reserved6; /* 保留字段 */
#define PMAP_TYPE_USER 0 /* ordinary pmap */
#define PMAP_TYPE_KERNEL 1 /* kernel pmap */
#define PMAP_TYPE_COMMPAGE 2 /* commpage pmap */
#define PMAP_TYPE_NESTED 3 /* pmap nested within another pmap */
uint8_t type; /* pmap 类型(用户、内核、commpage 或嵌套) */
decl_lck_rw_data(, txm_lck); /* 用于保护 TrustedExecutionMonitor 地址空间的读写锁 */
TXMAddressSpace_t *XNU_PTRAUTH_SIGNED_PTR("pmap.txm_addr_space") txm_addr_space; /* TrustedExecutionMonitor 地址空间 */
CSTrust_t txm_trust_level; /* TrustedExecutionMonitor 的信任级别 */
};
vm_map_entry
一个该结构表示一段连续的虚拟地址空间,它通过links连接整个任务的地址空间,如下:
struct vm_map_entry {
/* 链接到其他条目 */
struct vm_map_links links;
#define vme_prev links.prev /* 前一个条目 */
#define vme_next links.next /* 下一个条目 */
#define vme_start links.start /* 条目的起始地址 */
#define vme_end links.end /* 条目的结束地址 */
struct vm_map_store store; /* 存储一些额外信息,用于快速查改操作,如存储红黑树节点 */
/* 联合体:用于表示不同的上下文或对象类型,最重要的域,指向是最终对象还是子映射 */
union {
vm_offset_t vme_object_value; /* 对象的值 */
struct {
vm_offset_t vme_atomic:1; /* 条目不能被拆分或合并 */
vm_offset_t is_sub_map:1; /* 对象是否为子映射(submap) */
vm_offset_t vme_submap:VME_SUBMAP_BITS; /* 子映射的位字段 */
};
struct {
uint32_t vme_ctx_atomic : 1; /* 上下文相关的原子性标志 */
uint32_t vme_ctx_is_sub_map : 1; /* 上下文是否为子映射 */
uint32_t vme_context : 30; /* 上下文信息 */
/* 联合体:对象或偏移量,或标签的回溯引用 */
union {
vm_page_object_t vme_object_or_delta; /* 对象或偏移量 */
btref_t vme_tag_btref; /* 标签的回溯引用 */
};
};
};
/* 位字段:条目的 VM 标签 */
unsigned long long
/* vm_tag_t */ vme_alias:VME_ALIAS_BITS, /* 条目的 VM 标签 */
/* vm_object_offset_t*/ vme_offset:VME_OFFSET_BITS, /* 对象内的偏移量 */
/* 区域是否共享 */
/* boolean_t */ is_shared:1, /* 区域是否共享 */
/* 未使用的位 */
/* boolean_t */ __unused1:1,
/* 条目是否正在被修改 */
/* boolean_t */ in_transition:1, /* 条目是否正在被修改 */
/* 是否有等待者 */
/* boolean_t */ needs_wakeup:1, /* 是否有等待者 */
/* 用户分页行为提示 */
/* vm_behavior_t */ behavior:2, /* 用户分页行为提示 */
/* 对象是否需要复制 */
/* boolean_t */ needs_copy:1, /* 对象是否需要复制 */
/* 保护属性 */
#if defined(__arm64e__)
/* vm_prot_t-like */ protection:3, /* 保护代码 */
/* 是否用于可信路径 */
/* boolean_t */ used_for_tpro:1,
#else /* __arm64e__ */
/* vm_prot_t-like */ protection:4, /* 保护代码,bit3=UEXEC */
#endif /* __arm64e__ */
/* 最大保护属性 */
/* vm_prot_t-like */ max_protection:4, /* 最大保护,bit3=UEXEC */
/* 继承属性 */
/* vm_inherit_t */ inheritance:2, /* 继承属性 */
/* 是否使用嵌套的 pmap */
/* boolean_t */ use_pmap:1,
/* 新页面是否缓存 */
/* boolean_t */ no_cache:1, /* 新页面是否缓存 */
/* 映射是否不可移除 */
/* boolean_t */ vme_permanent:1, /* 映射是否不可移除 */
/* 是否使用超级页 */
/* boolean_t */ superpage_size:1, /* 是否使用超级页 */
/* 是否对齐到页大小 */
/* boolean_t */ map_aligned:1, /* 是否对齐到页大小 */
/* 是否清零固定页面 */
/* boolean_t */ zero_wired_pages:1, /* 是否清零固定页面 */
/* 是否用于 JIT */
/* boolean_t */ used_for_jit:1, /* 是否用于 JIT */
/* 是否与代码签名监控关联 */
/* boolean_t */ csm_associated:1, /* 是否与代码签名监控关联 */
/* 是否使用虚拟大小 */
/* boolean_t */ iokit_acct:1, /* 是否使用虚拟大小 */
/* 是否启用弹性代码签名 */
/* boolean_t */ vme_resilient_codesign:1, /* 是否启用弹性代码签名 */
/* 是否启用弹性媒体 */
/* boolean_t */ vme_resilient_media:1, /* 是否启用弹性媒体 */
/* 是否用于用户调试 */
/* boolean_t */ vme_xnu_user_debug:1, /* 是否用于用户调试 */
/* 是否禁用读时复制 */
/* boolean_t */ vme_no_copy_on_read:1, /* 是否禁用读时复制 */
/* 是否允许执行 */
/* boolean_t */ translated_allow_execute:1, /* 是否允许执行 */
/* 对象是否为内核对象 */
/* boolean_t */ vme_kernel_object:1; /* 对象是否为内核对象 */
/* 固定页面的计数 */
unsigned short wired_count; /* 可以分页如果 = 0 */
/* 用户固定页面的计数 */
unsigned short user_wired_count; /* 用于 vm_wire */
/* 调试相关字段 */
#if DEBUG
#define MAP_ENTRY_CREATION_DEBUG (1)
#define MAP_ENTRY_INSERTION_DEBUG (1)
#endif /* DEBUG */
#if MAP_ENTRY_CREATION_DEBUG
struct vm_map_header *vme_creation_maphdr; /* 创建时的映射头 */
uint32_t vme_creation_bt; /* 创建时的回溯引用 */
#endif /* MAP_ENTRY_CREATION_DEBUG */
#if MAP_ENTRY_INSERTION_DEBUG
uint32_t vme_insertion_bt; /* 插入时的回溯引用 */
vm_map_offset_t vme_start_original; /* 原始的起始地址 */
vm_map_offset_t vme_end_original; /* 原始的结束地址 */
#endif /* MAP_ENTRY_INSERTION_DEBUG */
};
vm_object
它表示一片连续的内存区域,如下:
struct vm_object {
/*
* 在 64 位系统上,我们将挂载在 memq 上的指针打包。
* 这些指针必须能够指向 memq。
* 打包的指针需要对齐到 64 字节边界,
* 这意味着对于 vm_object 来说有两点:
* (1) memq 结构体必须是结构体的第一个元素,以便我们可以控制其对齐;
* (2) vm_object 必须对齐到 64 字节边界。
* 对于静态的 vm_object,这是通过 'aligned' 属性实现的;
* 对于在 zone pool 中的 vm_object,这是通过将 vm_object 的大小舍入到最近的 64 字节大小来实现的。
*/
vm_page_queue_head_t memq; /* 常驻内存队列 - 必须是第一个元素,因为涉及压缩指针等,里面是vm_page链表 */
lck_rw_t Lock; /* 同步锁 */
union {
vm_object_size_t vou_size; /* 对象大小(仅在内部对象时有效) */
int vou_cache_pages_to_scan; /* 外部对象中尚未访问的页面数 */
} vo_un1;
struct vm_page *memq_hint; /* 内存队列的提示指针 */
int ref_count; /* 引用计数 */
unsigned int resident_page_count; /* 常驻页面数 */
unsigned int wired_page_count; /* 固定页面数 */
unsigned int reusable_page_count; /* 可重用页面数 */
struct vm_object *vo_copy; /* 接收更改页面的副本对象 */
uint32_t vo_copy_version; /* 副本版本号 */
uint32_t __vo_unused_padding; /* 未使用的填充 */
struct vm_object *shadow; /* 影子对象 */
memory_object_t pager; /* 数据来源的分页器 */
union {
vm_object_offset_t vou_shadow_offset; /* 影子对象中的偏移量 */
clock_sec_t vou_cache_ts; /* 外部对象在缓存中的时间戳 */
task_t vou_owner; /* 如果对象是可清除的或有 "ledger_tag",这是拥有它的任务 */
} vo_un2;
vm_object_offset_t paging_offset; /* 内存对象中的偏移量 */
memory_object_control_t pager_control; /* 数据返回的位置 */
memory_object_copy_strategy_t copy_strategy; /* 数据复制策略,包括:
MEMORY_OBJECT_COPY_SYMMETRIC:对称复制策略,多个 CoW 映射共享同一个 vm_object,直到发生写操作时,脏页会被复制到一个新的影子对象(shadow 字段指向原始对象)。
MEMORY_OBJECT_COPY_DELAY:延迟复制策略(非对称复制),vm_object 只保存部分数据,其余数据保存在另一个 vm_object 中(通过 copy 字段指向源对象),发生写操作时,副本对象会接收更改的页面,源对象保持不变。
MEMORY_OBJECT_COPY_NONE:无复制策略,需要逐页复制,速度较慢。
*/
/*
* 某些用户进程(主要是虚拟机软件)会获取大量 UPL(通过 IOMemoryDescriptors)
* 来固定大型 VM 对象中的页面,并溢出 16 位的 "activity_in_progress" 计数器。
* 由于我们从未强制执行任何限制,因此为了向后兼容,我们将其扩展到 32 位。
*/
unsigned short paging_in_progress:16; /* 分页进行中 */
unsigned short vo_size_delta; /* 对象大小的增量 */
unsigned int activity_in_progress; /* 活动进行中 */
/* 位字段:表示对象的各种状态和行为 */
unsigned int
/* boolean_t array */ all_wanted:6, /* 需要被唤醒的位数组 */
/* boolean_t */ pager_created:1, /* 分页器是否已创建 */
/* boolean_t */ pager_initialized:1, /* 分页器字段是否已初始化 */
/* boolean_t */ pager_ready:1, /* 分页器是否准备好接受请求 */
/* boolean_t */ pager_trusted:1, /* 分页器是否可信 */
/* boolean_t */ can_persist:1, /* 内核是否可以在所有地址映射引用解除分配后保留数据 */
/* boolean_t */ internal:1, /* 是否由内核创建 */
/* boolean_t */ private:1, /* 是否是私有对象 */
/* boolean_t */ pageout:1, /* 是否是页面换出对象 */
/* boolean_t */ alive:1, /* 是否尚未终止 */
/* boolean_t */ purgable:2, /* 可清除状态 */
/* boolean_t */ purgeable_only_by_kernel:1, /* 是否只能由内核清除 */
/* boolean_t */ purgeable_when_ripe:1, /* 是否在令牌成熟时清除 */
/* boolean_t */ shadowed:1, /* 是否存在影子对象 */
/* boolean_t */ true_share:1, /* 是否被多个地方映射 */
/* boolean_t */ terminating:1, /* 是否正在终止 */
/* boolean_t */ named:1, /* 是否具有内部命名约定 */
/* boolean_t */ shadow_severed:1, /* 影子对象是否被切断 */
/* boolean_t */ phys_contiguous:1, /* 内存是否物理连续 */
/* boolean_t */ nophyscache:1, /* 是否不允许主缓存 */
/* boolean_t */ for_realtime:1, /* 是否用于实时代码路径 */
/* vm_object_destroy_reason_t */ no_pager_reason:2, /* 无分页器的原因 */
#if FBDP_DEBUG_OBJECT_NO_PAGER
/* boolean_t */ fbdp_tracked:1, /* 是否被 FBDP 跟踪 */
__object1_unused_bits:2;
#else /* FBDP_DEBUG_OBJECT_NO_PAGER */
__object1_unused_bits:3;
#endif /* FBDP_DEBUG_OBJECT_NO_PAGER */
queue_chain_t cached_list; /* 可持久化对象的缓存列表 */
/* 以下字段不受任何锁保护,通过原子比较和交换更新 */
vm_object_offset_t last_alloc; /* 最后一次分配的偏移量 */
vm_offset_t cow_hint; /* 影子中存在但对象中不存在的最后一页 */
int sequential; /* 顺序访问大小 */
uint32_t pages_created; /* 创建的页面数 */
uint32_t pages_used; /* 使用的页面数 */
unsigned int
wimg_bits:8, /* 缓存 WIMG 位 */
code_signed:1, /* 页面是否已签名 */
transposed:1, /* 对象是否被转置 */
mapping_in_progress:1, /* 分页器是否正在映射/取消映射 */
phantom_isssd:1,
volatile_empty:1,
volatile_fault:1,
all_reusable:1,
blocked_access:1,
set_cache_attr:1,
object_is_shared_cache:1,
purgeable_queue_type:2,
purgeable_queue_group:3,
io_tracking:1,
no_tag_update:1, /* 是否不更新标签 */
#if CONFIG_SECLUDED_MEMORY
eligible_for_secluded:1, /* 是否有资格使用隔离内存 */
can_grab_secluded:1, /* 是否可以抓取隔离内存 */
#else /* CONFIG_SECLUDED_MEMORY */
__object3_unused_bits:2,
#endif /* CONFIG_SECLUDED_MEMORY */
#if VM_OBJECT_ACCESS_TRACKING
access_tracking:1, /* 是否启用访问跟踪 */
#else /* VM_OBJECT_ACCESS_TRACKING */
__unused_access_tracking:1,
#endif /* VM_OBJECT_ACCESS_TRACKING */
vo_ledger_tag:3, /* 对象的分类标签 */
vo_no_footprint:1; /* 是否不计入内存占用 */
#if VM_OBJECT_ACCESS_TRACKING
uint32_t access_tracking_reads; /* 访问跟踪的读取次数 */
uint32_t access_tracking_writes; /* 访问跟踪的写入次数 */
#endif /* VM_OBJECT_ACCESS_TRACKING */
uint8_t scan_collisions; /* 扫描冲突次数 */
uint8_t __object4_unused_bits[1]; /* 未使用的位 */
vm_tag_t wire_tag; /* 固定页面的标签 */
#if CONFIG_PHANTOM_CACHE
uint32_t phantom_object_id; /* 幻影对象的 ID */
#endif
#if CONFIG_IOSCHED || UPL_DEBUG
queue_head_t uplq; /* 未完成的 UPL 列表 */
#endif
#ifdef VM_PIP_DEBUG
/*
* 跟踪持有 "paging_in_progress" 引用的第一个持有者的堆栈跟踪。
*/
#define VM_PIP_DEBUG_STACK_FRAMES 25 /* 每个堆栈跟踪的深度 */
#define VM_PIP_DEBUG_MAX_REFS 10 /* 跟踪的引用数 */
struct __pip_backtrace {
void *pip_retaddr[VM_PIP_DEBUG_STACK_FRAMES];
} pip_holders[VM_PIP_DEBUG_MAX_REFS];
#endif /* VM_PIP_DEBUG */
queue_chain_t objq; /* 对象队列 - 目前用于可清除队列 */
queue_chain_t task_objq; /* 任务拥有的对象队列 - 受任务锁保护 */
#if !VM_TAG_ACTIVE_UPDATE
queue_chain_t wired_objq; /* 固定对象队列 */
#endif /* !VM_TAG_ACTIVE_UPDATE */
#if DEBUG
void *purgeable_owner_bt[16]; /* 可清除对象所有者的堆栈跟踪 */
task_t vo_purgeable_volatilizer; /* 使其易失的任务 */
void *purgeable_volatilizer_bt[16]; /* 使其易失的堆栈跟踪 */
#endif /* DEBUG */
};
内核中也存在一些全局的vm_object,如kernel_object_store用于管理内核的固定内存。
vm_page
struct vm_page {
union {
vm_page_queue_chain_t vmp_q_pageq; /* 用于 FIFO 队列或空闲链表的队列信息(受页队列锁保护) */
struct vm_page *vmp_q_snext; /* 下一个页面的指针 */
} vmp_q_un;
vm_page_queue_chain_t vmp_listq; /* 同一对象中的所有页面(受对象锁保护) */
vm_page_queue_chain_t vmp_specialq; /* 特殊队列中的匿名页面(受页队列锁保护) */
vm_object_offset_t vmp_offset; /* 页面在对象中的偏移量(受对象锁和页队列锁保护) */
vm_page_object_t vmp_object; /* 页面所属的对象(受对象锁和页队列锁保护),该物理页被使用时才有效 */
/*
* 以下标志字段过去由 "页队列" 锁保护。
* 现在不再如此,具体需要什么锁取决于 vmp_q_state 的值。
*
* 如果启用了本地队列,我们使用 'vmp_wire_count' 来存储本地队列 ID。
* 有关为什么这样做是安全的,请参阅 'vm_page_queues_remove' 的注释。
*/
#define VM_PAGE_SPECIAL_Q_EMPTY (0)
#define VM_PAGE_SPECIAL_Q_BG (1)
#define VM_PAGE_SPECIAL_Q_DONATE (2)
#define VM_PAGE_SPECIAL_Q_FG (3)
#define vmp_local_id vmp_wire_count
unsigned int vmp_wire_count:16, /* 有多少个固定映射使用此页面(受对象锁和页队列锁保护) */
vmp_q_state:4, /* 页面所在的队列状态(受页队列锁保护),含:
空闲(Free):页面未被使用,可以分配给新的内存请求。
活跃(Active):页面正在被使用。
非活跃(Inactive):页面不再被使用,但尚未被回收。
脏(Dirty):页面已被修改,需要写回后备存储。
清理中(Cleaning):页面正在被清理(写回后备存储)。
固定(Wired):页面被固定,不能被换出。
*/
vmp_on_specialq:2, /* 页面是否在特殊队列中 */
vmp_gobbled:1, /* 页面被内部使用(受页队列锁保护) */
vmp_laundry:1, /* 页面正在被清理(受页队列锁保护) */
vmp_no_cache:1, /* 页面不应被缓存,应优先重用(受页队列锁保护) */
vmp_private:1, /* 页面不应返回到空闲列表(受页队列锁保护) */
vmp_reference:1, /* 页面已被使用(受页队列锁保护) */
vmp_lopage:1, /* 页面是低优先级页面 */
vmp_realtime:1, /* 页面被实时线程使用 */
#if !CONFIG_TRACK_UNMODIFIED_ANON_PAGES
vmp_unused_page_bits:3; /* 未使用的位 */
#else /* ! CONFIG_TRACK_UNMODIFIED_ANON_PAGES */
vmp_unmodified_ro:1, /* 跟踪匿名页面在解压缩后是否被修改(受对象锁和页队列锁保护) */
vmp_unused_page_bits:2; /* 未使用的位 */
#endif /* ! CONFIG_TRACK_UNMODIFIED_ANON_PAGES */
/*
* 必须将这两个 32 位字的位字段分开,
* 因为编译器有将它们视为单个 64 位字段的坏习惯。
* 由于它们受不同的锁保护,这是一个真正的问题。
*/
vm_page_packed_t vmp_next_m; /* VP 桶链接(受对象锁保护) */
/*
* 以下标志字段受 "VM 对象" 锁保护。
*
* 重要提示:在持有 VM 对象 "共享" 锁和通过 pmap_lock_phys_page 函数获取的页面锁时,
* 可以修改 "vmp_pmapped"、"vmp_xpmapped" 和 "vmp_clustered" 位。
* 这是在 vm_fault_enter() 和 CONSUME_CLUSTERED 宏中完成的。
* 也可以仅在 VM 对象 "独占" 锁下修改它们。
*/
unsigned int vmp_busy:1, /* 页面正在传输中(受对象锁保护) */
vmp_wanted:1, /* 有人在等待此页面(受对象锁保护) */
vmp_tabled:1, /* 页面在 VP 表中(受对象锁保护) */
vmp_hashed:1, /* 页面在 vm_page_buckets[] 中(受对象锁和桶锁保护) */
vmp_fictitious:1, /* 物理页面不存在(受对象锁保护) */
vmp_clustered:1, /* 页面不是故障页面(受对象锁保护或对象共享锁和 pmap 页面锁保护) */
vmp_pmapped:1, /* 页面已进入 pmap(受对象锁保护或对象共享锁和 pmap 页面锁保护) */
vmp_xpmapped:1, /* 页面已以执行权限进入 pmap(受对象锁保护或对象共享锁和 pmap 页面锁保护) */
vmp_wpmapped:1, /* 页面已以写权限进入 pmap(受对象锁保护) */
vmp_free_when_done:1, /* 页面在清理完成后将被释放(受对象锁保护) */
vmp_absent:1, /* 数据已被请求,但尚不可用(受对象锁保护) */
vmp_error:1, /* 数据管理器由于错误无法提供数据(受对象锁保护) */
vmp_dirty:1, /* 页面必须被清理(受对象锁保护) */
vmp_cleaning:1, /* 页面清理已开始(受对象锁保护) */
vmp_precious:1, /* 页面是宝贵的;即使干净也必须返回数据(受对象锁保护) */
vmp_overwriting:1, /* 已发出解锁请求,但没有数据(受对象锁保护) */
vmp_restart:1, /* 页面被 copy_call 相关的分页器推高到影子链中,需要重新从链的顶部开始 */
vmp_unusual:1, /* 页面是缺席、错误、重启或页面锁定 */
vmp_cs_validated:VMP_CS_BITS, /* 代码签名:页面已通过验证 */
vmp_cs_tainted:VMP_CS_BITS, /* 代码签名:页面被污染 */
vmp_cs_nx:VMP_CS_BITS, /* 代码签名:页面是 nx */
vmp_reusable:1, /* 页面可重用 */
vmp_written_by_kernel:1; /* 页面由内核写入(例如解压缩) */
#if !defined(__arm64__)
ppnum_t vmp_phys_page; /* 页面的物理页号 */
#endif
};
vm_map_copy
它一个表示“传输中”内存区域复制操作的对象,定义如下:
struct vm_map_copy {
#define VM_MAP_COPY_ENTRY_LIST 1 /* 连续的虚拟内存区域,支持遍历和释放 */
#define VM_MAP_COPY_KERNEL_BUFFER 2 /* 处理内核缓冲区中的复制数据,支持动态大小的分配和释放,最大支持2页,使用kalloc分配 */
uint16_t type;
bool is_kernel_range;
bool is_user_range;
vm_map_range_id_t orig_range;
vm_object_offset_t offset;
vm_map_size_t size;
union {
struct vm_map_header hdr; /* ENTRY_LIST */
void *XNU_PTRAUTH_SIGNED_PTR("vm_map_copy.kdata") kdata; /* KERNEL_BUFFER */
} c_u;
};
memory_object
typedef struct memory_object {
mo_ipc_object_bits_t mo_ikot; /* IPC 对象类型(不可更改) */
#if __LP64__
#if XNU_KERNEL_PRIVATE
os_ref_atomic_t mo_ref;/* 在 LP64 架构上,有一个 4 字节的空洞,适合用作引用计数 */
#else
unsigned int __mo_padding;/* 非内核私有代码中的填充字段 */
#endif /* XNU_KERNEL_PRIVATE */
#endif /* __LP64__ */
const struct memory_object_pager_ops *mo_pager_ops; /* 分页器操作表 */
memory_object_control_t mo_control; /* 内存对象控制 */
} *memory_object_t;
upl
struct upl {
decl_lck_mtx_data(, Lock); /* 同步锁,用于保护 UPL 结构的并发访问 */
int ref_count; /* 引用计数,表示当前有多少地方引用了该 UPL */
int ext_ref_count; /* 外部引用计数,表示外部模块对该 UPL 的引用 */
int flags; /* 标志位,用于存储 UPL 的状态和行为控制 */
vm_object_offset_t u_offset; /* UPL 在内存对象中的偏移量(字节对齐) */
upl_size_t u_size; /* UPL 表示的地址空间大小(字节) */
upl_size_t u_mapped_size; /* UPL 中已映射部分的大小(字节) */
vm_offset_t kaddr; /* 内核中的二级映射地址 */
vm_object_t map_object; /* 关联的内存对象(vm_object_t) */
vector_upl_t vector_upl; /* 向量 UPL,用于支持多个 UPL 的聚合操作 */
upl_t associated_upl; /* 关联的 UPL,用于支持嵌套 UPL */
struct upl_io_completion *upl_iodone; /* I/O 完成回调函数 */
ppnum_t highest_page; /* UPL 中最高页面的物理页号(PPN) */
#if CONFIG_IOSCHED
int upl_priority; /* UPL 的 I/O 优先级 */
uint64_t *upl_reprio_info; /* I/O 优先级调整信息 */
void *decmp_io_upl; /* 解压缩 I/O 相关的 UPL */
#endif
#if CONFIG_IOSCHED || UPL_DEBUG
thread_t upl_creator; /* 创建该 UPL 的线程 */
queue_chain_t uplq; /* 对象上未完成 UPL 的链表 */
#endif
#if UPL_DEBUG
uintptr_t ubc_alias1; /* 调试用:UBC(Unified Buffer Cache)别名 1 */
uintptr_t ubc_alias2; /* 调试用:UBC 别名 2 */
uint32_t upl_state; /* UPL 的当前状态 */
uint32_t upl_commit_index; /* 提交索引,用于调试 */
uint32_t upl_create_btref; /* 创建时的回溯引用(btref_t) */
struct ucd upl_commit_records[UPL_DEBUG_COMMIT_RECORDS]; /* 提交记录 */
#endif /* UPL_DEBUG */
bitmap_t *lite_list; /* 轻量级页表列表 */
struct upl_page_info page_list[]; /* 页面信息数组,存储 UPL 中每个页面的状态 */
};
存在4种类型的UPL,它们在创建时由UPL_CREATE_*标志控制,并将类型写入flag字段,它们存在如下区别:
| 特性 | 外部 UPL | 内部 UPL | I/O UPL | 向量 UPL |
|---|---|---|---|---|
| 定义 | 与 map_object 绑定 |
页面信息存储在相邻缓冲区 | 轻量级 UPL,用于 I/O 操作 | 多个 UPL 的集合 |
| 默认类型 | 是(UPL_CREATE_EXTERNAL=0) |
否(需 UPL_INTERNAL 标志) |
否(需显式创建) | 否(需显式创建) |
| 关联对象 | map_object |
无 | 可以是 map_object 或内部 |
多个 UPL 的集合 |
| 页面信息存储 | 由 map_object 管理 |
upl_page_info 数组 |
wpl_array_t 轻量级列表 |
upl_elems 数组 |
| 使用场景 | 文件系统、内存映射 | 临时性内存操作 | I/O 操作(文件读写、设备传输) | VFS 层的集群读写操作(cluster_[read|write]_direct) |
| 优点 | 直接与后备存储交互 | 页面信息访问速度快 | 轻量级,适合高频次 I/O | 支持批量处理多个 UPL |
| 缺点 | 需要额外内存对象管理 | 内存占用较大,空间大小有限制 | 功能简化,不适合复杂操作 | 结构复杂,仅适用于特定场景 |
内存操作
内存分配
首先当然是最重要的内存分配咯,这里提供三类分配:
- vm_map_enter: 它是最底层的内存映射机制,其他所有机制都是基于它的,它被用于分配内核和用户态的虚拟内存,能满足各种复杂需求,速度也比较慢。
- kmem_alloc: 它用于内核中的有线(wired,即无法换出的)内存分配(当然也支持可分页的内存,见后文),常用于分配内核数据结构。
- kalloc: 它使用zone分配器来分配小块内存,大块会退化到
kmem_alloc。
他们关系如下:
用户/驱动请求
│
├─ kalloc / kalloc_type ← 通用小对象分配器 (zone/slab + 大块回退)
│ │
│ └─ zalloc_ext() ← zone allocator(slab路径)
│ └─ kalloc_large() ← 大块路径,内部调用 ↓
│
├─ kmem_alloc ← 内核专用有线/可分页内存
│ │
│ └─ kmem_alloc_guard_internal()
│ │
│ ├─ vm_page_alloc_list() ← 直接分配物理页
│ └─ vm_map_find_space() ← 调用 ↓
│
└─ vm_map_enter ← VM层最低级原语,建立VA→对象映射
下面详细介绍这三类分配机制。
vm_map_enter
vm_map_enter 是XNU虚拟内存子系统中建立虚拟地址映射的核心原语,它处于整个内存管理层次的中间位置,向上提供VM分配能力,向下连接着物理页表建立逻辑:
用户态系统调用
mmap() / mach_vm_allocate() / vm_allocate()
↓ BSD 层 kern_mman.c
vm_map_enter_mem_object() ← 用户态文件映射入口
vm_map_enter_mem_object_prefault()
↓ Mach VM 层
vm_map_enter() ← 核心原语(本函数)
↓ 操作 vm_map_entry 链表
vm_map_entry_insert() ← 插入新 entry
vm_map_locate_space_anywhere/fixed() ← 寻找地址空间
↓
pmap(物理页表) ← 实际的硬件页表只在 page fault 时才填写
它是在指定的vm_map中,为一段虚拟地址范围建立一条vm_map_entry 记录,将这段虚拟地址与某个vm_object的某个偏移关联起来,并设置访问权限、继承属性等。注意它只建立VM层的映射描述,不会立刻填写硬件页表(pmap),真正的物理页分配和页表填写发生在后续的page fault处理中。
它的签名如下:
/* osfmk/vm/vm_map.c */
kern_return_t vm_map_enter(
vm_map_t map, // 目标虚拟地址空间
vm_map_offset_t *address, // IN/OUT:请求/返回的起始虚拟地址
vm_map_size_t size, // 映射大小(页对齐,即为页的整数倍大小)
vm_map_offset_t mask, // 地址对齐掩码(用于ANYWHERE模式)
vm_map_kernel_flags_t vmk_flags, // 各种标志位
vm_object_t object, // 要映射的vm_object(NULL=匿名内存)
vm_object_offset_t offset, // 在vm_object中的偏移
boolean_t needs_copy, // 是否Copy-On-Write
vm_prot_t cur_protection, // 当前权限(r/w/x)
vm_prot_t max_protection, // 最大允许权限,mprotect上限,之后修改权限只能不高于它
vm_inherit_t inheritance) // fork 时子进程如何继承
下面列出一些比较重要的vmk_flags 标志位:
| 标志 | 含义 |
|---|---|
vmf_fixed |
必须是指定地址(MAP_FIXED),不搜索空闲区 |
vmf_overwrite |
覆盖已有映射 |
vmf_purgeable |
内存可被内核在内存压力时回收 |
vmkf_map_jit |
JIT区域(MAP_JIT) |
vmkf_submap |
映射对象是子map,不是vm_object |
vmkf_nested_pmap |
使用nested pmap(dyld 共享缓存) |
vmf_permanent |
不可被 munmap 移除 |
vmf_tpro |
TPRO(线程保护只读) |
vmf_resilient_codesign |
代码签名容错映射 |
vmf_4gb_chunk |
最大4GB分块 |
vmf_random_addr |
随机化地址(ASLR) |
这个函数极其庞大,下面分阶段简单描述:
入口先执行各种校验(Pre-flight Checks):
1. superpage检查: 若请求huge page,校验大小、对齐,禁止继承
2. W^X策略执行(注:CSM豁免(dynamic-codesigning)的进程跳过此检查):
- iOS(alien map):有W+X但无 MAP_JIT → 剥掉X权限(strip)
- macOS:有W+X但无MAP_JIT → 直接 KERN_PROTECTION_FAILURE(fail)
3. JIT区域验证: iOS上MAP_JIT必须有RWX,否则拒绝
4. 可执行锁定: map->map_disallow_new_exec时拒绝任何X权限映射
5. resilient_codesign/resilient_media的约束检查
6. TPRO约束检查,并降级cur_protection为只读(pmap层负责W/R切换)
7. submap约束(不能purgable、page size必须匹配)
8. `vmkf_already`语义检查(只能配合fixed+non-overwrite)
9. size/offset对齐检查
接着获取ma 锁,搜索可用的地址空间 :
vm_map_lock(map); // 独占锁,保护整个vm_map链表
if (anywhere) {
// ANYWHERE模式: 在可用地址空间中找一段足够大的空洞
vm_map_locate_space_anywhere(map, size, mask, vmk_flags, address, &entry);
// → 遍历hole list或RB树,找到满足mask对齐的空闲区间
// → JIT区域额外使用随机地址(ASLR)
} else {
// FIXED模式: 在指定地址处寻找/清空空间
vm_map_locate_space_fixed(map, start, size, mask, vmk_flags, &entry, &zap_old_list);
// → 若有overwrite标志,把已有entry放入zap_old_list待删除
}
start = *address;
end = start + size;
尝试快速路径,即如果新区域和前一个 entry相邻且属性完全相同则进行合并,直接扩展已有 entry,避免创建新节点:
// 合并条件(需要同时满足 20+ 个条件)
if ((is_submap == FALSE) &&
(object == VM_OBJECT_NULL) && // 都是匿名内存
(entry->vme_end == start) && // 地址连续
(entry->protection == cur_protection) && // 权限相同
(entry->max_protection == max_protection) &&
(entry->inheritance == inheritance) &&
(!entry->used_for_jit && !entry_for_jit) && // 非JIT
// ... 还有15+个条件 ...
(entry->wired_count == 0)) {
if (vm_object_coalesce(...)) {
entry->vme_end = end; // 直接扩展!
map->size += ...;
RETURN(KERN_SUCCESS); // 提前返回
}
}
如果无法合并,则进入主循环:
for (tmp2_start = start; tmp2_start < end; tmp2_start += step) {
do {
// 特殊情况: purgable/JIT/TPRO/malloc_no_cow → 需要提前创建vm_object
if (purgable || entry_for_jit || ...) {
if (object == VM_OBJECT_NULL) {
object = vm_object_allocate(size, map->serial_id);
// JIT object额外设置: vo_inherit_copy_none = true
// purgable object加入purgeable队列
}
}
// 核心: 插入新map entry,它会从zone allocator分配entry,关联vm_object,如果是jit会在map里标明jit exist,然后插入RB树+链表
new_entry = vm_map_entry_insert(map,
entry, tmp_start, tmp_end,
object, offset, vmk_flags,
needs_copy, cur_protection, max_protection,
inheritance);
// 设置特殊属性
if (resilient_codesign) new_entry->vme_resilient_codesign = TRUE;
if (resilient_media) new_entry->vme_resilient_media = TRUE;
if (iokit_acct) new_entry->iokit_acct = TRUE; // IOKit计费
// submap 处理: 嵌套pmap(dyld 共享缓存)
if (is_submap && use_pmap) {
pmap_nest(map->pmap, submap->pmap, tmp_start, ...);
new_entry->use_pmap = TRUE; // nested pmap立即生效!
}
// superpage: 立刻分配物理连续内存并装入vm_object
if (superpage_size) {
cpm_allocate(SUPERPAGE_SIZE, &pages, ...);
sp_object = vm_object_allocate(...);
vm_page_insert_wired(m, sp_object, ...);
}
} while (tmp_end < tmp2_end); // 继续下一个chunk
}
new_mapping_established = TRUE;
接着进行资源限制检查:
// RLIMIT_AS检查(进程地址空间总大小限制)
if (map->size > map->size_limit) → KERN_NO_SPACE
// RLIMIT_DATA检查(数据段大小限制)
if (map->size > map->data_limit) → KERN_NO_SPACE
如果成功,对于命名(named)外部内存对象(如文件映射),需要通知分页器:
// 调用memory_object_map(),告知pager这段内存被映射了
// pager可据此跟踪引用计数、决定何时可以回收
memory_object_map(pager, pager_prot);
如果失败就是回滚+收尾:
// 成功 → 如果需要wire,立刻wire所有页(wiring_required || superpage)
if (map->wiring_required || superpage_size) {
vm_map_wire_nested(map, start, end, ...);
}
// 失败 → 原子清理新建的mapping
if (new_mapping_established) {
vm_map_delete(map, *address, *address + size, ...);
}
// 失败 + 有被覆盖的旧mapping → 尝试恢复旧mapping(zap_old_list)
if (vm_map_zap_first_entry(&zap_old_list)) {
// 把旧entries重新插回map
vm_map_store_entry_link(map, entry1, entry2, ...);
}
vm_map_unlock(map);
vm_fault
前面并没有把它放在内存分配里,因为它就不是正常的内存分配函数,但是它是真正分配pmap的地方,所以这里单独拿来讲!vm_map_enter只建立了虚拟内存表,任务在使用该区域的内存时由于没有物理内存所以会触发缺页异常,流程如下:
硬件异常触发
↓
1. sleh_sync() [osfmk/arm64/sleh.c]
↓ (根据异常类型分发)
↓
2. handle_abort() [osfmk/arm64/sleh.c:1489]
↓ (调用 inspect_data_abort/inspect_instruction_abort 分析故障)
↓
3a. handle_user_abort() [用户态缺页, sleh.c:1846]
或
3b. handle_kernel_abort() [内核态缺页, sleh.c:2128]
↓ (判断 is_vm_fault())
↓ (快速路径: 检查是否只是引用/修改位故障)
↓
4. arm_fast_fault() [快速处理pmap层面的故障,处理访问位/修改为故障]
↓ (如果失败)
↓
5. vm_fault() [osfmk/vm/vm_fault.c:4195]
↓
6. vm_fault_internal() [核心处理函数 vm_fault.c:4380]
↓
├─→ vm_map_lookup_and_lock_object() [查找并锁定VM对象]
↓
├─→ 快速路径(Fast Path) [直接在当前对象查找页面并映射,持有锁时间短 vm_fault.c:4787开始]
│ ├─→ vm_page_lookup() [在对象中查找页面]
│ ├─→ 页面已存在且有效
│ └─→ goto FastPmapEnter [vm_fault.c:5151]
│
└─→ 慢速路径 (Slow Path) [需要遍历shadow chain、pager读取或分配新页面 handle_copy_delay, vm_fault.c:6145]
↓
7. vm_fault_page() [vm_fault.c:1090] - 慢速路径核心
↓
├─→ 遍历 shadow chain (影子链)
│ ├─→ vm_page_lookup() 在当前对象查找页面
│ ├─→ 如果找到: 处理页面状态 (busy/laundry/error等)
│ └─→ 如果未找到: 移动到 shadow 对象继续查找
↓
├─→ 页面不存在的情况:
│ ├─→ 检查是否需要从 pager 获取
│ ├─→ MUST_ASK_PAGER() 检查压缩器或外部 pager
│ ├─→ 分配新页面 vm_page_grab_options()
│ ├─→ 从 pager 读取数据 (memory_object_data_request)
│ └─→ 零填充 vm_fault_zero_page()
↓
8. FastPmapEnter: [vm_fault.c:5151]
↓
9. vm_fault_enter() [vm_fault.c:4066]
↓
├─→ vm_fault_enter_prepare() [准备和验证页面]
│ └─→ 代码签名验证、压缩页面处理等
↓
└─→ vm_fault_pmap_enter_with_object_lock()
└─→ pmap_enter() [将页面映射到物理地址空间]
└─→ 更新页表、TLB 等
这里可以注意一下vm_fault_enter,它是之后要讲的代码签名验证的一个重要位置!
kmem_alloc
它是专为内核代码设计的,分配有线虚拟内存的接口,比如内核、扩展等会使用,它是wired的,即立即分配无法换出,它的分配单位是page size,可分配任意大(当然现实中一定要谨慎使用避免浪费),其实现为:
static inline kern_return_t kmem_alloc(
vm_map_t map,
vm_offset_t *addrp,
vm_size_t size,
kma_flags_t flags,
vm_tag_t tag
)
/*
kmem_alloc(map, addrp, size, flags, tag)
└─ kernel_memory_allocate() // inline 包装
└─ kmem_alloc_guard_internal() // 核心实现
├─ vm_page_alloc_list() // 1.预先分配物理页列表
├─ vm_object_allocate() // 2.新建 vm_object (或复用 kernel_object)
└─ vm_map_find_space() // 3.建立 VA 映射
└─ vm_map_enter() // 最终调用
*/
kalloc
它类似于用户态的malloc,是内核中高效的小对象分配器,它内部使用zone allocator(slab分配)处理小块,如果遇到超大块会退回到kmem_alloc:
void *kalloc(vm_size_t size)
/*
kalloc_ext(kheap, size, flags, owner)
├─ kalloc_zone_for_size_with_flags() // 找对应的zone(size ≤ KHEAP_MAX_SIZE)
│ └─ kalloc_zone() // slab路径
│ └─ zalloc_ext() // 从zone freelist取元素
│
└─ kalloc_large() // size > KHEAP_MAX_SIZE(16K/32K)
└─ kmem_alloc_guard() // 回退到kmem路径
*/
不过这种只指定大小不指定类型的内存分配方式容易出现类型混淆漏洞,所以apple安全团队一直在慢慢引入类型概念,并最终在21年正式引入kalloc_type宏来替代原来的kalloc,所以这里着重讲下kalloc_type,它让编译器在编译时就知道分配什么类型的内存,从而实现类型隔离,具体来说它分成了四大堆:
typedef struct kalloc_heap {
zone_stats_t kh_stats;
const char *__unsafe_indexable kh_name;
zone_kheap_id_t kh_heap_id;
vm_tag_t kh_tag;
uint16_t kh_type_hash;
zone_id_t kh_zstart;
struct kalloc_heap *kh_views;
} *kalloc_heap_t;
每个堆在 VA 空间中独立隔离:
| 堆名 | 用途 | 安全特性 |
|---|---|---|
KHEAP_DEFAULT |
通用内核对象(含指针的结构体) | zone 内部隔离 |
KHEAP_DATA_BUFFERS |
纯数据(不含指针):用户拷入数据、NFS 缓冲、协议栈数据等 | 独立子图(submap),防数据喷射 |
KHEAP_DATA_SHARED |
可跨 kernel/user 或 kernel/DMA 共享的纯数据 | 进一步与 DATA_BUFFERS 隔离 |
KHEAP_KT_VAR |
变长 kalloc_type 分配的临时堆 |
过渡中,未来合入类型系统 |
所有kalloc API都接受 zalloc_flags_t:
__options_decl(zalloc_flags_t, uint32_t, {
Z_WAITOK = 0x0000, // 允许睡眠等待,不可耗尽的 zone 永不失败
Z_NOWAIT = 0x0001, // 绝不阻塞,可能失败(中断上下文使用)
Z_NOPAGEWAIT = 0x0002, // 锁等待OK,但不等待 VM 分页
Z_ZERO = 0x0004, // 返回前清零
Z_REALLOCF = 0x0008, // realloc 失败时释放原内存
Z_NOFAIL = 0x8000, // 宣称绝不失败,否则 panic(不能与 Z_NOWAIT 同用)
// 组合常量:
Z_WAITOK_ZERO = Z_WAITOK | Z_ZERO,
Z_WAITOK_ZERO_NOFAIL = Z_WAITOK | Z_ZERO | Z_NOFAIL,
});
在每个kalloc_type/kfree_type调用点,编译器都会生成一个静态的kalloc_type_view,放在 __DATA_CONST,__kalloc_type 段里,启动时被 XNU 处理器扫描,决定这个类型去哪个 zone:
```336:353:osfmk/kern/kalloc.h struct kalloc_type_view { struct zone_view kt_zv; // 指向 zone const char *kt_signature; // 编译器生成的类型签名字符串 kalloc_type_flags_t kt_flags; // KT_DATA_ONLY / KT_VM / KT_PTR_ARRAY... uint32_t kt_size; // sizeof(type) zone_t kt_zearly; // 启动早期共享 zone zone_t kt_zsig; // 按签名分配的 zone };
类型签名(kt_signature)由编译器内置函数 `__builtin_xnu_type_signature` 在编译时计算,每 8 字节(granule)编码为:
| granule 类型 | 编码值 | 含义 |
| -------------------- | ------ | ---------------- |
| `KT_GRANULE_PADDING` | 0 | 填充字节 |
| `KT_GRANULE_DATA` | 2 | 普通标量(非指针) |
| `KT_GRANULE_POINTER` | 1 | 指针 |
| `KT_GRANULE_PAC` | 8 | PAC 签名指针 |
相同签名的结构体 → 分到同一个zone,实现type isolation。
现在给出一些使用案例,首先是`kalloc_type`,它有多种变体:
```c
/* 固定大小,分配单个对象的声明 */
#define kalloc_type(type, flags)
// case1
struct thread_exception_elt *elt =
kalloc_type(struct thread_exception_elt, Z_WAITOK | Z_NOFAIL);
/* 变长,分配同类元素数组 */
#define kalloc_type(e_type, count, flags)
// case2
thread_array = kalloc_type(thread_t, active_thread_count, Z_WAITOK);
/* 变长,带 header 的结构体 + 变长数组 */
#define kalloc_type(hdr_type, e_type, count, flags)
// case3
struct task_watchports *watchports = kalloc_type(struct task_watchports,
struct task_watchport_elem, count, Z_WAITOK | Z_ZERO | Z_NOFAIL);
// 这里等价于
struct {
struct task_watchports hdr;
struct task_watchport_elem arr[]; // [count] 个
};
如果是不含脂针的纯数据缓冲区,也可以用kalloc_data,它走KHEAP_DATA_BUFFERS:
// XNU 内部定义:
#define kalloc_data(size, flags) kheap_alloc(GET_KEXT_KHEAP_DATA(), size, flags)
#define kfree_data(elem, size) kheap_free(GET_KEXT_KHEAP_DATA(), elem, size)
// kext/外部接口:
extern void *kalloc_data(vm_size_t size, zalloc_flags_t flags);
extern void kfree_data(void *ptr, vm_size_t size);
内存移动与复制
相关函数如下:
vm_map_copy_t vm_map_copy_allocate(void); /* 从 vm_map_copies 区域中分配一个 vm_map_copy 对象 */
kern_return_t vm_map_copyin(vm_map_t src_map, vm_map_address_t src_addr, vm_map_size_t len, boolean_t src_destroy, vm_map_copy_t *copy_result); /* 从源地址空间复制内存并创建 vm_map_copy 对象 */
kern_return_t vm_map_copyin_kernel_buffer(vm_map_t src_map, vm_map_address_t src_addr, vm_map_size_t len, vm_map_copy_t *copy_result); /* 从内核缓冲区中复制数据并创建 vm_map_copy 对象 */
kern_return_t vm_map_copyout(vm_map_t dst_map, vm_map_address_t *dst_addr, vm_map_copy_t copy); /* 将 vm_map_copy 对象插入目标地址空间的未使用区域 */
kern_return_t vm_map_copy_overwrite(vm_map_t dst_map, vm_map_address_t dst_addr, vm_map_copy_t copy, boolean_t interruptible); /* 将 vm_map_copy 对象覆盖到目标地址空间的现有区域 */
kern_return_t vm_map_copy_overwrite_aligned(vm_map_t dst_map, vm_map_address_t dst_addr, vm_map_copy_t copy, boolean_t interruptible); /* 将 vm_map_copy 对象覆盖到目标地址空间的现有区域(确保对齐) */
void vm_map_copy_discard(vm_map_copy_t copy); /* 释放 vm_map_copy 对象及其关联的资源,比如复制失败时 */
void vm_map_copy_copy(vm_map_copy_t src_copy, vm_map_copy_t dst_copy); /* 将一个 vm_map_copy 对象的内容复制到另一个对象中 */
上面已经提到有两种复制方式,如果是小对象可以用kernel_buffer,它从kalloc.xx分配空间(动态大小),并将数据直接复制到它里面;而其他情况使用entry_list型,它从vm_map_copies区域分配空间(固定大小),然后通过遍历源空间复制entry信息。这里的copy_in和copy_out可以分开调用,一个指向源一个指向目标,从而可以跨进程复制。另外在复制时,copyout是没有指定目标位置的,它复制到任意位置,通常是exec用,更常用的是copy_overwrite,它是复制到指定位置。最后再提一嘴vm_read和vm_write它们都是这几个函数的封装。
分页机制
大多数系统不可避免地使用比可用 RAM 更多的虚拟内存。因此,通常说物理内存充当虚拟内存的窗口,因为虚拟内存会从后备存储(backing store)分页到物理页面中,或从物理页面分页回后备存储。后备存储通常是更持久的存储形式,例如(命名的)文件或(匿名的)交换空间、设备,甚至是另一种形式的内存,例如加密或压缩的 RAM。
秉承其微内核起源,Mach 支持外部内存管理器(EMMs)的概念,通常称为分页器(pagers)。分页器是一个对象,其目的是处理虚拟内存与其后备存储之间的分页操作。使用分页器完全隐藏了这些操作的实现细节,使其调用者——vm_pageout 守护进程——无需了解分页操作的具体细节。实际操作可以通过内联、专用线程、由内核扩展(kext)实现,甚至在理论上可以分页到远程后备存储。相反,分页器不涉及分页策略,而只是按照页面守护进程的指示实现低级操作。
在某些方面,当前的内存管理实现自其诞生以来已经有所退化。原始设计允许内存管理器成为一个真正的外部实体(即位于内核空间之外),通过 Mach 端口和消息进行通信。
原始的分页器实现——默认分页器,处理匿名(交换)内存——从 Mach 早期一直使用到 XNU-3248,之后被移除,转而使用压缩器(compressor)。分页器机制很容易扩展到新的后备存储类型,苹果已经多次利用这一事实,添加了自己的分页器,最终在 Darwin 18 中达到了七种分页器:
| 分页器类型 | 实现位置 | 后备存储 |
|---|---|---|
| Vnode | osfmk/vm/bsd_vm.c |
Vnodes(从文件映射的数据,mmap(2)) |
| Device | osfmk/vm/device_vm.c |
设备 |
| Apple Protect | osfmk/vm/vm_apple_protect.c |
加密内存 |
| swapfile | osfmk/vm/vm_swapfile_pager.c |
交换文件 vnodes |
| Compressor | osfmk/vm/vm_compressor_pager.c |
压缩 RAM(Darwin 13) |
| 4K | osfmk/vm/vm_fourk_pager.c |
在 16K 页面上模拟 4K 页面(Darwin 15) |
| shared | osfmk/vm/vm_shared_region_pager.c |
DYLD 共享缓存(Darwin 18) |
分页器需要实现(和按需扩展)memory_object对象,它里面的mo_pager_ops用于实现具体的操作,当然也不用全部实现:
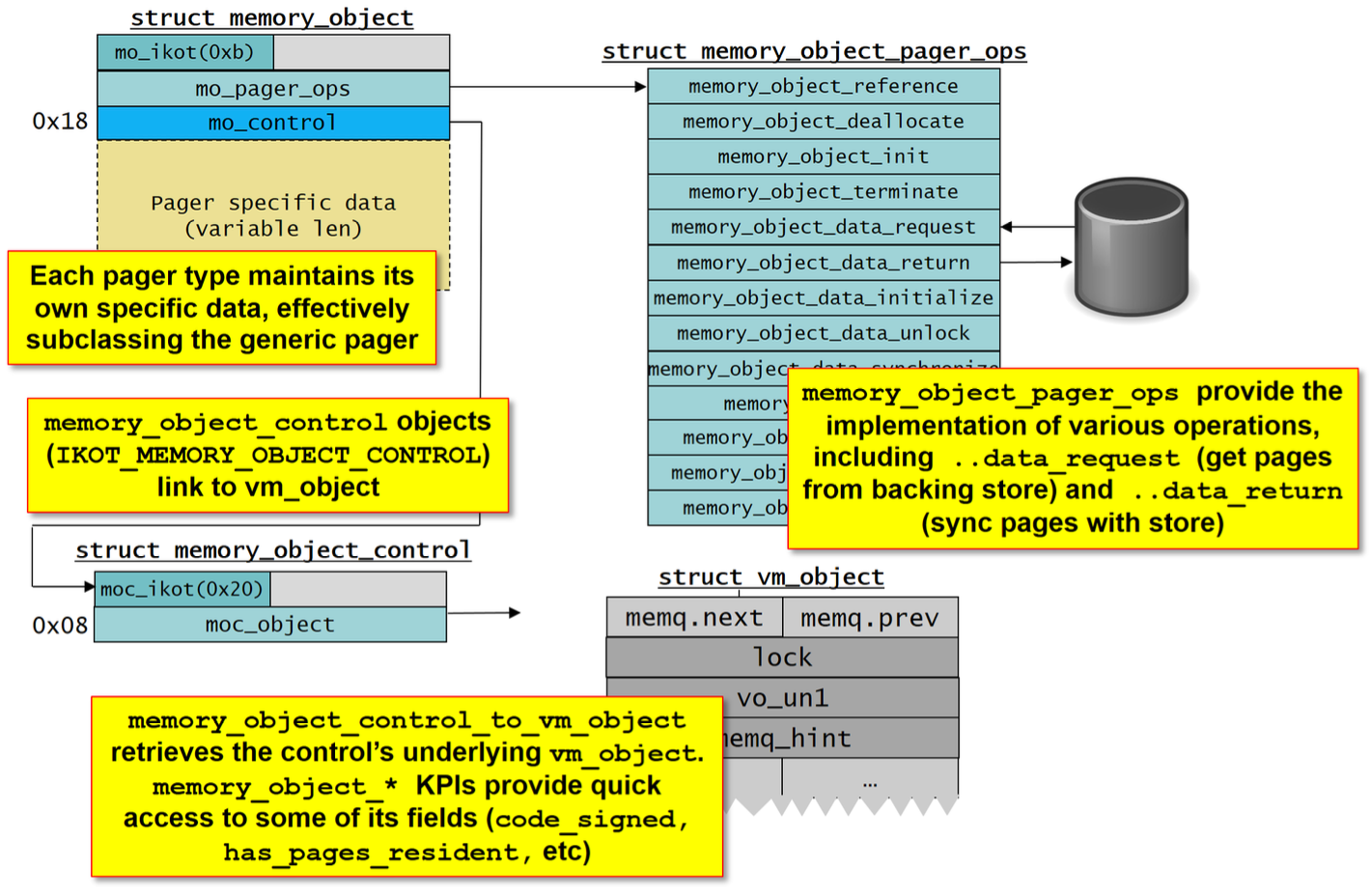
typedef const struct memory_object_pager_ops {
/* 增加内存对象的引用计数 */
void (*memory_object_reference)(memory_object_t mem_obj);
/* 减少内存对象的引用计数,如果引用计数为 0,则释放内存对象 */
void (*memory_object_deallocate)(memory_object_t mem_obj);
/* 初始化内存对象 */
kern_return_t (*memory_object_init)(
memory_object_t mem_obj, /* 内存对象 */
memory_object_control_t mem_control, /* 内存对象控制 */
memory_object_cluster_size_t size /* 内存对象大小 */
);
/* 终止内存对象 */
kern_return_t (*memory_object_terminate)(memory_object_t mem_obj);
/* 处理数据请求 */
kern_return_t (*memory_object_data_request)(
memory_object_t mem_obj, /* 内存对象 */
memory_object_offset_t offset, /* 请求的偏移量 */
memory_object_cluster_size_t length, /* 请求的长度 */
vm_prot_t desired_access, /* 请求的访问权限 */
memory_object_fault_info_t fault_info /* 故障信息 */
);
/* 处理数据返回 */
kern_return_t (*memory_object_data_return)(
memory_object_t mem_obj, /* 内存对象 */
memory_object_offset_t offset, /* 返回数据的偏移量 */
memory_object_cluster_size_t size, /* 返回数据的大小 */
memory_object_offset_t *resid_offset, /* 剩余偏移量 */
int *io_error, /* I/O 错误 */
boolean_t dirty, /* 数据是否脏 */
boolean_t kernel_copy, /* 是否由内核复制 */
int upl_flags /* UPL 标志 */
);
/* 初始化数据 */
kern_return_t (*memory_object_data_initialize)(
memory_object_t mem_obj, /* 内存对象 */
memory_object_offset_t offset, /* 初始化数据的偏移量 */
memory_object_cluster_size_t size /* 初始化数据的大小 */
);
#if XNU_KERNEL_PRIVATE
/* 以下字段已废弃 */
void *__obsolete_memory_object_data_unlock;
void *__obsolete_memory_object_synchronize;
#else
/* 解锁数据(已废弃) */
kern_return_t (*memory_object_data_unlock)(
memory_object_t mem_obj,
memory_object_offset_t offset,
memory_object_size_t size,
vm_prot_t desired_access
);
/* 同步数据(已废弃) */
kern_return_t (*memory_object_synchronize)(
memory_object_t mem_obj,
memory_object_offset_t offset,
memory_object_size_t size,
vm_sync_t sync_flags
);
#endif /* !XNU_KERNEL_PRIVATE */
/* 映射内存对象 */
kern_return_t (*memory_object_map)(
memory_object_t mem_obj, /* 内存对象 */
vm_prot_t prot /* 映射的保护权限 */
);
/* 最后一次取消映射 */
kern_return_t (*memory_object_last_unmap)(memory_object_t mem_obj);
#if XNU_KERNEL_PRIVATE
/* 以下字段已废弃 */
void *__obsolete_memory_object_data_reclaim;
#else
/* 回收数据(已废弃) */
kern_return_t (*memory_object_data_reclaim)(
memory_object_t mem_obj,
boolean_t reclaim_backing_store
);
#endif /* !XNU_KERNEL_PRIVATE */
/* 获取内存对象的后备对象 */
boolean_t (*memory_object_backing_object)(
memory_object_t mem_obj, /* 内存对象 */
memory_object_offset_t mem_obj_offset, /* 内存对象的偏移量 */
vm_object_t *backing_object, /* 后备对象 */
vm_object_offset_t *backing_offset /* 后备对象的偏移量 */
);
/* 分页器的名称 */
const char *memory_object_pager_name;
} * memory_object_pager_ops_t;
UPL
在使用时需要先创建UPL,内核中有多种方式能创建,但它们最终都会调到upl_create(),UPL 会在最接近其结构大小的区域(zone)中通过 kalloc() 分配内存,并且(如果是 UPL_INTERNAL 类型)还会分配额外的 upl_page_info 数组。创建后,由分页器等处理它们,并通常在提交(commit)或中止(abort)后结束其生命周期,提交意味着将页面刷新回其后备存储(通过 vm_pageout 守护进程代码),并在引用计数为0时释放它们,相关函数如下:
/* 创建 UPL */
int ubc_create_upl(vnode_t vp, off_t offset, int size, upl_t *upl); // 为 vnode 创建新的 UPL,填充其 vm_object(在 Darwin 17 中移除)。
int ubc_create_upl_external(vnode_t vp, off_t offset, int size, upl_t *upl); // 同上,但用于外部(kext)调用者。
int ubc_create_upl_kernel(vnode_t vp, off_t offset, int size, upl_t *upl); // 同上,但用于内核内部使用。
int vm_map_create_upl(vm_map_t map, vm_map_offset_t offset, vm_map_size_t size, upl_t *upl); // 由 VM 映射处理层调用以创建 UPL。
int vm_object_upl_request(vm_object_t object, vm_object_offset_t offset, vm_object_size_t size, upl_t *upl); // 由 VM 对象处理层调用以请求 UPL。
int vm_object_iopl_request(vm_object_t object, vm_object_offset_t offset, vm_object_size_t size, upl_t *upl); // 由 VM 对象处理层调用以请求 I/O UPL。
int memory_object_upl_request(memory_object_t pager, memory_object_offset_t offset, memory_object_size_t size, upl_t *upl); // 由分页器调用以请求 UPL。
int memory_object_iopl_request(memory_object_t pager, memory_object_offset_t offset, memory_object_size_t size, upl_t *upl); // 由分页器调用以请求 I/O UPL。
int vector_upl_create(int count, upl_t *upl); // 由 VFS 层的 cluster_[write/read]_direct 使用以创建向量 UPL。
/* 操作UPL */
int ubc_upl_abort(upl_t upl); // 中止(丢弃)整个 UPL 中的页面。
int ubc_upl_abort_range(upl_t upl, int offset, int size); // 中止(丢弃)UPL 中指定范围的页面。
int ubc_upl_commit(upl_t upl); // 提交(将页面刷新到后备存储)整个 UPL。
int ubc_upl_commit_range(upl_t upl, int offset, int size); // 提交(将页面刷新到后备存储)UPL 中指定范围的页面。
int ubc_upl_map(upl_t upl, vm_map_t map, vm_map_offset_t *addr); // 将关联的页面列表映射到内核虚拟地址空间。
int ubc_upl_unmap(upl_t upl); // 将关联的页面列表从内核虚拟地址空间中取消映射。
int ubc_upl_pageinfo(upl_t upl, upl_page_info_t *page_info); // 检索标记为 UPL_INTERNAL 的 UPL 的内部页面列表。
int ubc_upl_range_needed(upl_t upl, int offset, int size); // 指定所需的页面范围。
/* 释放UPL */
void upl_destroy(upl_t upl); // 销毁 UPL 并释放其内存(如果引用计数为零)。
void upl_deallocate(upl_t upl); // 释放 UPL 并可选调用 upl_callout_iodone()。
Mach原语层内存管理
我们研究*OS系统时通常会分四层,内存部分也不例外,可分为用户态 C 库、BSD/POSIX系统调用层、Mach原语层和Mach内核层,在这里先插入一个整体层次:
用户态程序
│
├─ malloc / free / realloc / calloc ← 用户态堆分配器(libmalloc)
│ ↓ (超大块 or mmap区)
├─ POSIX/BSD 系统调用(kern_mman.c)
│ mmap / munmap / mprotect / madvise / msync / mlock / mincore ...
│ ↓
├─ Mach 原语层(vm_user.c → libsyscall/mach_vm.c)
│ mach_vm_allocate / mach_vm_map / mach_vm_protect / mach_vm_remap ...
│ ↓
└─ Mach 内核层(vm_map_enter / vm_fault / pmap)
mach原语极其重要,后面会有文章专门介绍,这里只列出一些api,它们和BSD层一样能直接在用户态被调用(Mach Trap),不像BSD api,这些api是可以操作任意任务的:
| 接口 | 对应 BSD/功能 | 说明 |
|---|---|---|
mach_vm_allocate(task, addr, size, flags) |
等价 mmap(MAP_ANON) |
分配匿名VM区域 |
mach_vm_deallocate(task, addr, size) |
等价 munmap |
释放VM区域 |
mach_vm_protect(task, addr, size, set_max, prot) |
等价 mprotect |
修改权限,set_max=true 时改的是 max_protection |
mach_vm_map(task, addr, size, mask, flags, obj, offset, copy, cur_prot, max_prot, inherit) |
比 mmap 更底层 |
可指定 vm_object(memory entry port)、max_protection、继承策略 |
mach_vm_remap(task, addr, size, ..., src_task, src_addr, copy, ...) |
无 POSIX 等价 | 跨进程重新映射,复制或共享另一个进程的地址空间区域 |
mach_vm_remap_new |
同上,更新版 | cur/max protection为inout参数 |
mach_vm_read(task, addr, size, ...) |
无 POSIX 等价 | 读取另一进程的内存(调试/注入) |
mach_vm_write(task, addr, data, ...) |
无 POSIX 等价 | 写入另一进程的内存 |
mach_vm_copy(task, src, size, dst) |
无 POSIX 等价 | 在同一地址空间内复制区域(CoW 优化) |
mach_vm_msync |
等价 msync |
同步映射区到pager |
mach_vm_wire(host_priv, task, addr, size, access) |
等价 mlock |
需要host_priv端口,锁定物理页 |
mach_vm_behavior_set |
等价 madvise |
设置内存访问模式hint |
mach_vm_region(task, addr, size, flavor, info, ...) |
无 POSIX 等价 | 查询VM区域信息(相当于解析 vmmap 输出) |
mach_vm_purgable_control |
无 POSIX 等价 | 控制purgeable内存的状态 |
mach_vm_page_query |
无 POSIX 等价 | 查询单个页的物理状态(驻留/脏/引用等) |
BSD层内存管理
这就是一个转换层,就是实现了我们熟悉的POSIX系统调用,其实内部是封装为Mach原语执行的,这里就简单列一下吧:
// 映射内存/文件:mmap → mmap_sanitize() → vm_map_enter_mem_object() → vm_map_enter()
mmap(proc_t p, struct mmap_args *uap, user_addr_t *retval)
// 解除映射:直接调用mach_vm_deallocate,移除vm_map_entry,页面进入inactive队列
munmap(__unused proc_t p, struct munmap_args *uap, __unused int32_t *retval)
// 修改内存保护权限:mach_vm_protect() → vm_map_protect() → 更新 vm_map_entry.protection,并调用 pmap_protect() 更新页表
mprotect(__unused proc_t p, struct mprotect_args *uap, __unused int32_t *retval)
// 内存使用建议:mach_vm_behavior_set() → 更新vm_map_entry.behavior,影响vm_fault中的预读策略
madvise(__unused proc_t p, struct madvise_args *uap, __unused int32_t *retval)
// 同步映射内存到文件:mach_vm_msync() → vm_map_msync() → memory_object_synchronize()
msync(__unused proc_t p, struct msync_args *uap, int32_t *retval)
// 查询页是否在物理内存中
mincore(__unused proc_t p, struct mincore_args *uap, __unused int32_t *retval)
// 锁定物理内存:这个函数需要特权,执行路径为mach_vm_wire() → vm_map_wire() → 对每个物理页调用vm_page_wire()
mlock(__unused proc_t p, struct mlock_args *uap, __unused int32_t *retvalval)
// POSIX共享内存:共享同一vm_object(MEMORY_OBJECT_TYPE_SHM)
shm_open(name, flags, mode) // 创建/打开
shm_unlink(name) // 删除
ftruncate(fd, size) // 设置大小
// SysV共享内存
shmget(key, size, flags) // 创建/获取SysV共享内存段,返回shmid
shmat(shmid, shmaddr, flags) // 附加(attach)到进程地址空间
shmdt(shmaddr) // 分离(detach)出进程地址空间
shmctl(shmid, cmd, buf) // 控制/删除共享内存段
用户态内存管理
这就是我们熟悉的libc(不过这里实际是libSystem)内存分配函数处,它兼容POSIX,所以长相大差不差,只是参数上有扩展能力,这里简单列下:
| 接口 | 说明 |
|---|---|
malloc(size) |
通用分配,内部按size走Nano/Tiny/Small/Medium/Large不同子堆 |
calloc(n, size) |
分配并清零(malloc + bzero) |
realloc(ptr, size) |
调整已分配块大小 |
free(ptr) |
释放,小块归还给 zone freelist,大块调用 mach_vm_deallocate |
posix_memalign(ptr, align, size) |
对齐分配 |
valloc(size) |
页对齐分配(等价于 posix_memalign(..., PAGE_SIZE, ...) ) |
malloc_size(ptr) |
查询malloc块的实际可用大小 |
这里的子堆为:
- Malloc Nano: ≤256B,每线程独立,超低开销
- Malloc Tiny: ≤1016B,位图bitmap freelist
- Malloc Small: ≤15360B,freelist链
- Malloc Large: 超出Small,调
mach_vm_allocate,每次一个独立 VM region
参考
-
ARM® Architecture Reference Manual ARMv8, for ARMv8-A architecture profile:The AArch64 Virtual Memory System Architecture
-
ARM体系结构编程域实践 -- 奔跑吧Linux社区[编著]
-
*OS Internals: Volume II -- Jonathan Levin
-
Modern iOS Security Features – A Deep Dive into SPTM, TXM, and Exclaves