本文是学习PT SWARM的研究文章[7] [8] [9] [10]的笔记,主要内容都是来自这几篇文章!
编译v8
我用的是m1,参考Compiling on Arm64 Linux进行编译:
# 1. 安装最新版的xcode(嗯,只是要新点的mac sdk)
# 2. 下载工具
git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git
export PATH="$PATH:/path/to/depot_tools"
# 3. 同步源码
mkdir chromium && cd chromium
caffeinate fetch --no-history chromium # caffeinate防止休眠 --no-history 不要整个历史数据
# 安装CCache来加速构建
brew install ccache
# 指定参数
gn args out/Default
cc_wrapper="env CCACHE_SLOPPINESS=time_macros ccache"
is_component_build = true # 组件构建,之后重新编译速度会快很多(缺点是启动要慢点)
is_debug = true # 调试模式
symbol_level = 2 # 开启调试符号
临时查看可以使用chromium code search,不过真要阅读还得本地,文档Compiling on Arm64 Linux说apple silicon需要做额外的配置,但现在不做这些操作也能成功编译了
注:现在国内没有镜像源了,克隆代码一定要开tunnel等模式;如果还是失败可以先用git克隆代码,再用gclient管理!
IDE
为了搜索(交叉引用)和调试,当然ide里打开更方便了,使用gn help gen可见它能生成vs/xcode等所需的项目文件,对于clion党它也能通过gn生成json格式的编译数据库或通过创建简易的cmakelists来获取代码分析能力,细节可见文档Chromium Docs: CLion Dev
V8解释器
总览
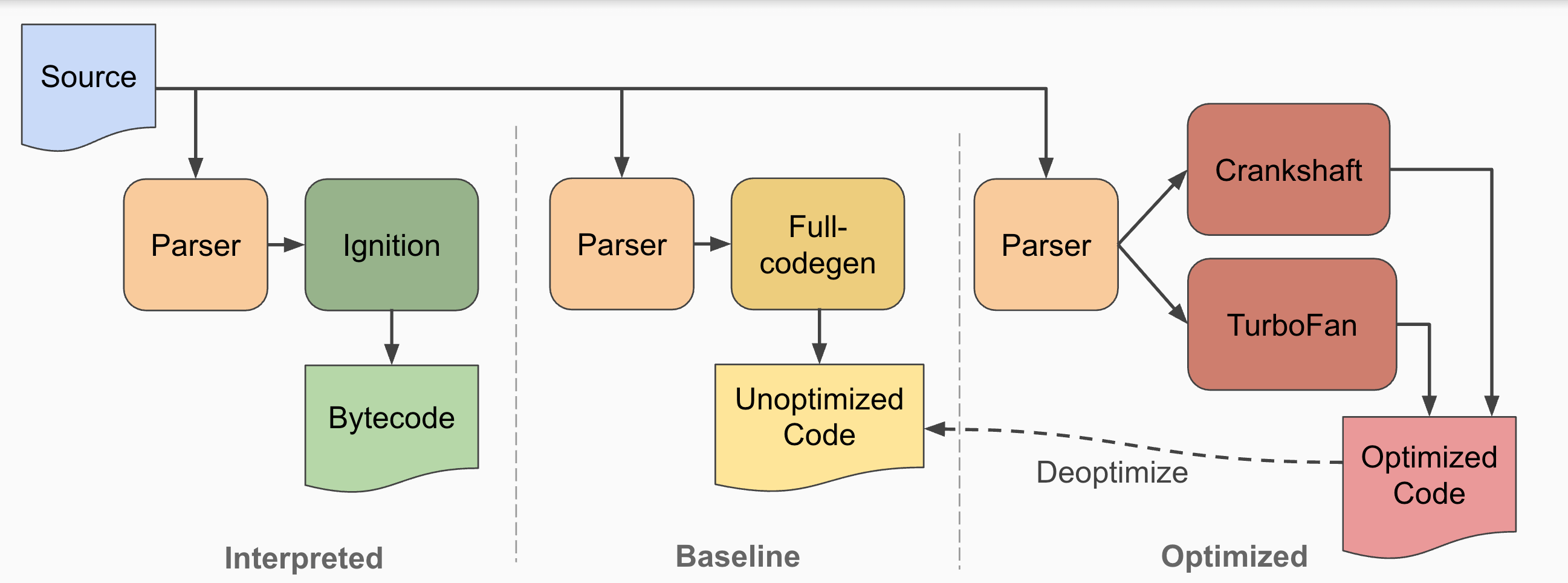
V8当年一发布就震惊全场,10多年过去了它也进化了好几代了,今天的主角ignition是就最新的字节码解释器,不过还是提一嘴历史,有四个东东:
1.Full-CodeGen:它直接将js转换为本地代码,显然它是没有任何优化的,速度最慢,它作为性能基线;它在执行时可搜集数据用于CrankShaft生成优化后的代码
2.CrankShaft:这是JIT编译器,有基于类型反馈的优化了,但是难以适应新的ES特性;当优化失败可退回到全代码生成的结果去执行
3.TurboFan:它与Ignition解释器协同工作,当V8识别出“热点代码”时,TurboFan会将Ignition生成的字节码编译成高度优化的机器码,它采用多种优化技术,如函数内联、死代码消除、数值范围分析等,以确保JavaScript代码尽可能快地运行
4.Ignition:解释器和字节码生成器,它首先将JavaScript代码解析成抽象语法树(AST),然后将其转换为紧凑的字节码格式,再交给TurboFan执行
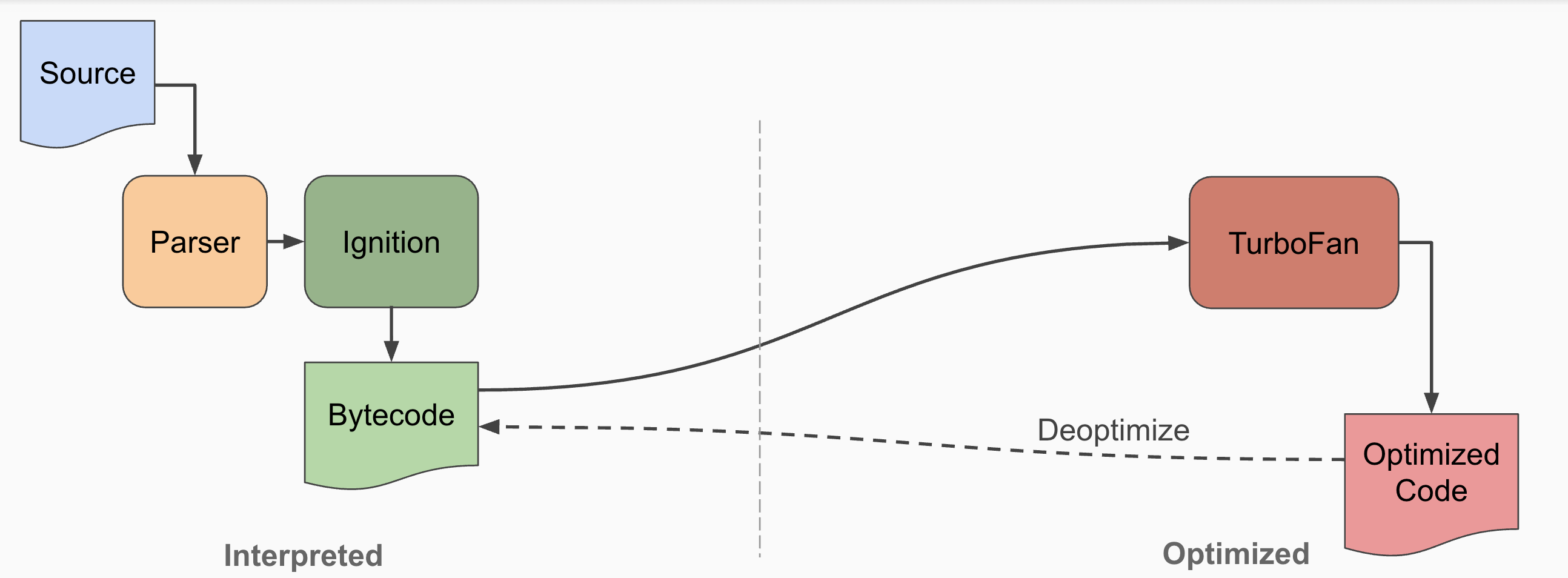
现在最新的版本只有Ignition和TurboFan了:
dispatcher结构
虚拟机通常是取指->译码->执行,在解释器上通常是在一个while-switch里解释每条指令,但现代解释器几乎不会用这种形式,这里先说下常见的dispathcer结构[13]:
1.Switch Dispatch:这个最常见,特点是简单但速度慢
2.Direct Threaded:它直接编码字节码handler的地址作为一个数组,每次执行完跳到下一个地址(这其实可以也看作是做了尾调用优化):
void* bytecode[] = { &&op_add, &&op_sub, ... };
pc = &bytecode[0];
goto **pc;
op_add:
// ... 加法操作
pc++;
goto **pc;
op_sub:
// ...
3.Indirect Threaded/Token Threaded:相比直接线索更加了一层
4.Subroutine Threaded/Call Threaded:类似于Direct Thread,但是不是用goto而是用函数调用来执行handler,结构清晰但速度会更慢点:
void op_add(void);
void op_sub(void);
void (*bytecode[])(void) = { op_add, op_sub, ... };
pc = &bytecode[0];
while (true) {
void (*instruction)(void) = *pc++;
instruction();
}
5.Replicationed Switch-based Dispatching:Switch Dispatch的优化版本,它没有了while循环,而是在每个指令结束后复制switch结构来实现解码跳转,这种方式会也是空间换时间:
#define DISPATCH() \
opcode = *pc++; \
switch (opcode) { \
case OP_ADD: goto label_add; \
case OP_SUB: goto label_sub; \
/* ... */ \
}
// 开始
DISPATCH();
label_add:
// 执行加法...
DISPATCH(); // 在末尾直接分派下一条
label_sub:
// 执行减法...
DISPATCH(); // 在末尾直接分派下一条
Ignition采用的是Indirect Threaded;除了常见的dispatch优化,指令上常见的还有Super Instructions是对一些高频连续指令,直接用一条新指令代替,减少分派耗时;Selective Inline直接在handler的末尾,直接看下一条操作码,如果经常执行的就直接把handler的内容复制过来,去执行而少了一次分派。
字节码生成
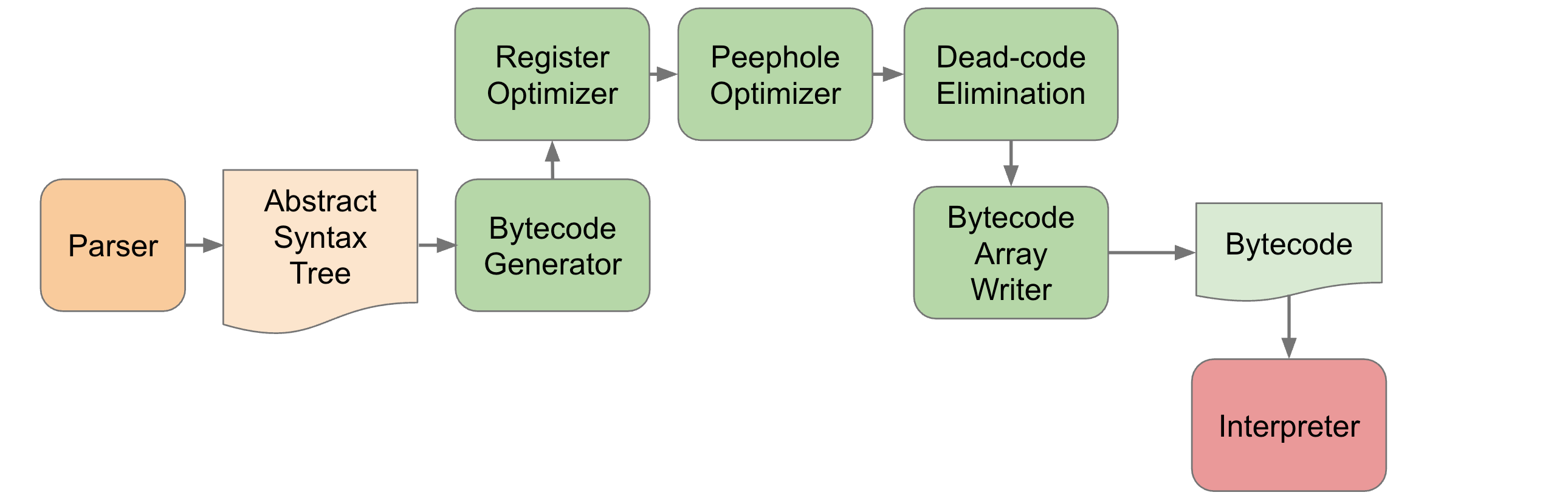
当 V8 第一次编译一个 JS 函数时(非优化编译阶段),V8 的解析器(Parser)会读取 JavaScript 源码,并将其转换成AST,然后BytecodeGenerator开始工作,它其实是个AST Visitor,它会按一定顺序遍历AST节点,每到一个节点它会根据节点类型生成一个或多个与之对应的字节码指令;不过BytecodeGenerator并不直接负责拼接原始的二进制字节码,而是交给了BytecodeArrayBuilder,BytecodeArrayBuilder会自动选择合适的操作数宽度来生成最优的指令:
void BytecodeGenerator::VisitAddExpression(BinaryOperation* expr) {
Register lhs = VisitForRegisterValue(expr->left());
VisitForAccumulatorValue(expr->right());
builder()->AddOperation(lhs);
}
这里生成的字节码就是我们的主角,它被存储在SharedFunctionInfo之上,可被Ignition直接执行,也可作为TurboFan的输入来构建优化的代码。
Handler生成
Ignition并不是直接写CPP解释执行字节码,而是根据字节码生成(通过CodeStubAssembler实现)一个中间表示TurboFan IR,然后交给TurboFan执行,TurboFan再做各种优化后翻译为目标平台上的机器代码:
void Interpreter::DoAdd(InterpreterAssembler* assembler) {
Node* reg_index = assembler->BytecodeOperandReg(0); // 获取第一个操作数
Node* lhs = assembler->LoadRegister(reg_index); // 根据索引加载对应寄存器的值
Node* rhs = assembler->GetAccumulator();
Node* result = AddStub::Generate(assembler, lhs, rhs); // 相加
assembler->SetAccumulator(result); // 存储结果到累加器
assembler->Dispatch(); // 调度到下一个字节码的处理器
}
turbofan提供三级IR:
1.JavaScript: JavaScript的重载操作,如JSAdd/JSCall/JSSubtract等
2.Simplified/Intermediate: 虚拟机级操作,如NumberAdd/NumberSubtract等
3.Machine: 本机级操作,每个平台需有对应的实现,如Int32Add/Int64Add等
好了,据最新情报(2025:Land ahoy: leaving the Sea of Nodes),v8放弃节点之海咯!
函数调用
1.一个 JS 函数的入口地址被设置为一个名为 InterpreterEntryTrampoline 的特殊内置存根(stub)
2.当这个 JS 函数在运行时被调用,程序首先进入 InterpreterEntryTrampoline
3.这个“蹦床(Trampoline)”存根的主要工作是为这次函数调用建立一个解释器所需的栈帧(Stack Frame)
4.准备工作完成后,它会查找该函数的第一条字节码,并从全局调度表中找到其对应的处理器,然后跳转过去,从而正式开始在解释器中执行函数
基于寄存器和累加器
Ignition 是一个基于寄存器的解释器,函数的局部变量、中间计算结果等值,都被存放在一个“虚拟寄存器文件”(Register File)中,这个所谓的寄存器文件其实是分配在函数栈帧上的一块内存区域中的特定“槽位(slots),字节码指令通过其操作数来明确指定它们要读取或写入哪个虚拟寄存器;为了进一步优化性能和减小字节码体积,它还引入了累加器Acc,不像其它虚拟寄存器它会努力的将累加器映射到物理寄存器来提高性能。
BytecodeGenerator在生成字节码时,就规划好了整个函数需要多少个虚拟寄存器,以及它们分别用于什么目的,要分为三类:
1.局部变量 (Local Variables):由于 JavaScript 的变量声明(var, let, const)在语法分析阶段会被“提升(hoisted)”,所以一个函数有多少个局部变量是提前可知的,BytecodeGenerator 会在处理 AST 的初始阶段,就为每一个局部变量分配一个固定的、不会改变的寄存器索引。
2.上下文指针 (Context Pointers):用于实现闭包的上下文对象的数量和层级也是在语法分析阶段就确定了的,因此也可以被提前分配好固定的寄存器槽位。
3.临时值 (Temporary Values):这是最复杂的部分。在计算复杂表达式时(例如 a + b * c),需要临时空间来存放中间结果(比如 b * c 的结果),BytecodeGenerator 使用一种“作用域化的寄存器分配器(scoped BytecodeRegisterAllocator)”来处理。可以把它想象成:
-
每处理一条语句(statement),就拿到一块“临时草稿板”。
-
在这条语句内部的表达式计算时,可以随时在草稿板上申请临时空间来存放中间值。
-
当这条语句处理完毕,这块“草稿板”就被丢弃,所有临时空间都被释放。
BytecodeGenerator 会在整个函数生成过程中,持续追踪“草稿板”在哪个时刻被使用得最多(即峰值),并记录下这个最大值。最终,函数总的寄存器文件大小 = 局部变量数 + 上下文数 + 所需临时寄存器的峰值。
因为虚拟寄存器本质上就是栈上的槽位,所以 V8 将这个概念扩展,把栈帧上的其他重要数据也看作是虚拟寄存器,并为它们分配了固定的“寄存器”名称或索引,包括:
1.函数参数: 传入函数的参数(包括隐式的 this)本身就位于栈上,Ignition 可以直接通过寄存器索引去访问它们,就像访问局部变量一样
2.上下文和闭包指针:由函数调用者推到栈上的当前上下文(Register::current_context())、当前函数闭包对象(Register::function_closure())等,也可以被字节码指令直接当作寄存器来访问
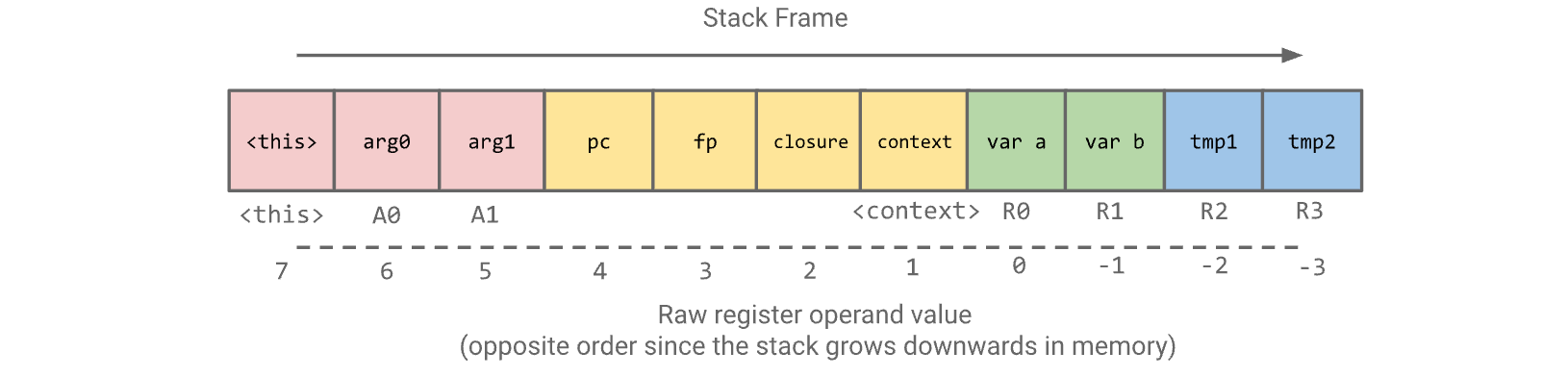
上下文
在上下文这一块概念比较多,一个一个讲:
首先是作用域(Scope),在ES6以前JS只有两个作用域,全局作用域和函数作用域,此时使用var声明变量或普通的函数声明都会在当前作用域里,会存储在一个叫变量环境(Variable Environment)的结构里,它们在编译阶段就有了,所以var和函数有个提升(Hoist)的概念,即使用可以在定义之前,而没有使用var声明的变量直接赋值在宽松模式会赋给全局作用域(严格模式抛ReferenceError)。
在ES6之后,新出了块级作用域,与它们关联的let和const两个关键字,不像函数作用域只有一个,每出现一层{}就会有一个新的块级作用域,当在新的块里使用这let/const定义变量或常量时,它们不会存储于上面提到的变量环境里,而是这一个块的词法环境(Lexcical Environment)中!查找时也是先把本函数的词法环境找完了再找变量环境再找外层的。
注:其实ES6之前也有个例外,
try...catch的catch子句是一个局部作用域,外部是无法访问的
接着说查找,我们都知道在一个局部访问变量,若它没有在当前作用域,编程语言通常允许像外层查找,但下面的情况可能令人迷惑:
int a = 1;
void foo(){
console.log(a);
}
foo();
void bar(){
int a = 2;
foo();
}
foo函数输出的是1还是2,即它是向函数定义处的外层查找还是函数使用处的外层查找,这要因此另外两个概念:
1.静态作用域(Static Scope)/ 词法作用域(Lexcical Scope):一个变量的作用域在编译时就确定了,不会随运行时改变,它首先在自己内部作用域中查找,若没有则去其定义时所在外部作用域中查找,逐步向上知道全局作用域
2.动态作用域(Dynamic Scope):变量的作用域在运行时才能确定,变量的查找取决于程序执行流程,它首先还是从内部找,若找不到则跟着函数的调用栈一层一层往上找
JS(应该说绝大多数现代编程语言)都是用的词法作用域,俺暂时还没见过动态作用域,但说这个是为了引出闭包,它是根据这几条规则出来的:
1.函数是一等公民:它能作为一个值被返回到外层
2.使用词法作用域:函数内部可以访问函数定义处外部的变量
3.函数的局部变量声明周期随函数执行结束而消亡:返回的函数引用外层函数的局部变量时,那些局部变量又必须要可访问
它的解决办法就是将要用到的局部变量从栈转移到堆上去!
现在来说另一个概念,执行上下文(Excution Context),它由三部分组成:词法环境(含本地let/const和外部环境引用)、变量环境(var/function def)、this,前两个已经讲了,还剩this,不过要说this得先说执行上下文,执行上下文是 JavaScript 代码在执行时所处的环境,每当 JavaScript 引擎准备执行一段代码时,它都会先创建一个执行上下文,JS中主要有三种:
1.全局执行上下文 (Global Execution Context - GEC):这是最基础的上下文,代码开始执行时首先进入的就是这个环境,一个程序中只有一个全局执行上下文,它会创建一个全局对象(在浏览器中是 window,在 Node.js 中是 global),并且 this 在默认情况下会指向这个全局对象
2.函数执行上下文 (Function Execution Context - FEC):这是最常见的上下文,每当一个函数被调用时,就会为该函数创建一个新的执行上下文,每个函数调用都有自己独立的上下文,互不干扰,这也是为什么递归函数能够正常工作的原因
3.Eval 执行上下文 (Eval Execution Context):当代码在 eval() 函数内部执行时,会创建这种上下文,由于 eval() 的性能和安全问题,在现代 JavaScript 开发中已不推荐使用,所以这种上下文也比较少见
执行上下文会确定并存储当前环境中的this,全局最简单,对于函数则由函数被调用方式决定,如作为对象的方法调用、使用 new 关键字调用、通过 call/apply/bind 调用,或作为普通函数调用它们会动态指向。
JS代码在访问一个变量时,若在当前环境中找不到,则会沿着它的词法作用域引用从内到外寻找,即查作用域链(Scope Chain),上面已经提到它采用静态作用域,也就是说它寻找到目标其实在编译时是确定的,所以v8在字节码生成时就做了优化,直接标明了在第几层作用域的第几个,通过一次性直接访问就能加载它避免了运行时查找损耗。
堆
V8的大多数数据都在堆上,且JS本身没有显式free对象的操作,堆上的数据都是自动垃圾回收的,为此需要关注两部分:
1.哪些对象应该被GC:V8采用用可访问性(reachability)算法来判断堆中的对象是否还存活,如果从所有GC Roots都无法访问到那它就是垃圾该被回收了
2.何时怎么GC:GC的性能优化至关重要,GC时需要停止虚拟机执行(Stop-The-World),并且可能会有大量内存移动/复制操作,这些都是极其耗性能的操作,顾需要在其中寻求平衡,V8根据代际假说(The Generational Hypothesis)将内存主要分为两块,新生代和老生代,以及根据一些特定用途分区,下面简单描述下堆类型:
1.NEW_SPACE (新生代空间):绝大多数新创建的对象都首先被分配在这里,它的空间很小(通常只有1-8MB),垃圾回收非常频繁且速度极快。它采用Scavenge (清道夫)算法:
-
新生代内部又被平分为两个等大的半空间(Semi-space):From-Space 和 To-Space
-
对象总是被分配在From-Space,当From-Space快满时,GC启动
-
GC会找出From-Space中所有仍然存活的对象,并将它们复制到To-Space
-
复制完成后,From-Space里剩下的就全是垃圾了,可以直接清空
-
最后,From-Space和To-Space的角色互换
2.OLD_SPACE (老生代空间):在新生代中经过两轮GC后仍然存活的对象,会被“晋升”到老生代空间,这个区域的空间较大,垃圾回收的频率比新生代低很多。它采用Mark-Sweep(标记-清除)算法,但这会产生碎片,于是通常还有Mark-Compact(标记-整理)去移动对象:
-
标记 (Mark): 从根对象(如全局对象)开始,遍历所有可达的对象,并打上“存活”标记
-
清除 (Sweep): 遍历整个老生代空间,回收所有没有被标记的(即垃圾)对象所占用的内存
-
整理 (Compact): (可选步骤)将所有存活的对象向空间的一端移动,以解决内存碎片化问题
3.LO_SPACE (大对象空间, Large Object Space):需要连续大量内存的“大”对象。一个对象如果超过了特定的大小阈值(比如比单个Semi-space的一半还大),就会被直接分配在这里,它里面的每个对象都独占一个或多个内存页,一旦分配,永远不会被移动;它不使用独立的GC算法,而是由老生代的Mark-Sweep来统一管理;GC会标记它是否存活,如果死亡则直接回收其占用的内存页
-
CODE_SPACE (代码空间):存放TurboFan生成的已编译的机器代码
-
MAP_SPACE (映射空间):专门存放对象的隐藏类 (Hidden Classes,在V8中称为Maps)
异常处理
JS使用try...catch...finally来表示异常处理,在编译时它采用了无性能损耗的方式,即若无异常则无损耗,为此它用了一个叫 exceptionn andler table的专用结构存储try{}块的起止信息、CatchPrediction、异常处理程序地址等信息,当出现异常时,就可以根据它快速跳转到异常处理程序了,当然了它也有栈展开(Stack Unwinding)机制,当前没有找到合适的会回溯栈找,最后还没有就崩溃!
隐藏类
基于两个事实,属性固定的对象可极大优化属性的访问速度及对象很少会新增或删除属性,v8在内部为每个对象创建了一个隐藏类(map),并且多个对象若属性名、数量、顺序都一样则可以共用隐藏类。
V8 Snapshot File
JavaScript规范包括很多内置功能,从数学函数到全功能的正则表达式引擎。每个新创建的V8上下文从一开始就具有这些功能。为了使其工作,全局对象(例如,浏览器中的窗口对象)和所有内置功能必须在创建上下文时设置并初始化到V8的堆中。每次从头开始做这件事需要相当长的时间,于是V8提出了快照来加速这个过程,它是在V8初始化后,执行其它操作前(这个之间可以插入自己编写大函数等,但不能执行它们),直接转储整个堆(后来有了lazy deserialize去针对性转储[19]来减小快照大小),之后直接加载这个快照即可,而且它还很贴心的堆Math.random/Date.now等做了修补保证正确性[5]。
本来这是为了优化启动速度,但是它实际会将JS编译为字节码存储,于是也能一定程度的保护软件不被分析[6],而分析它也是本文的目标!
先看怎么使用,可以直接在v8里调用:
const char* source =
"function f() { return g() * 2; }"
"function g() { return 43; }"
"/./.test('a')";
v8::StartupData data = v8::V8::CreateSnapshotDataBlob(source);
但更简单的方式是用bytenode,它实际也是调用的同样的功能!
关于快照文件,详见v8源码和插件源码,有空再叙~
V8 ByteCode
总览:

指令操作数说明
1.reg:寄存器
2.imm:立即数,直接编码在指令中的小整数 (smi)
3.idx:索引,指向常量池(Constant Poll)
4.id:各种id,如函数id等
5.offset:跳转指令的偏移量
指令详解
宽指令
除了运行时函数调用的ID是16位,大多数指令默认操作数是8位,但有时操作数大于8位,就要用前缀标识,存在两种前缀:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| Wide | 0x00 | 表示这个操作数有16位 | |
| Extra | 0x01 | 表示这个操作数有32位 |
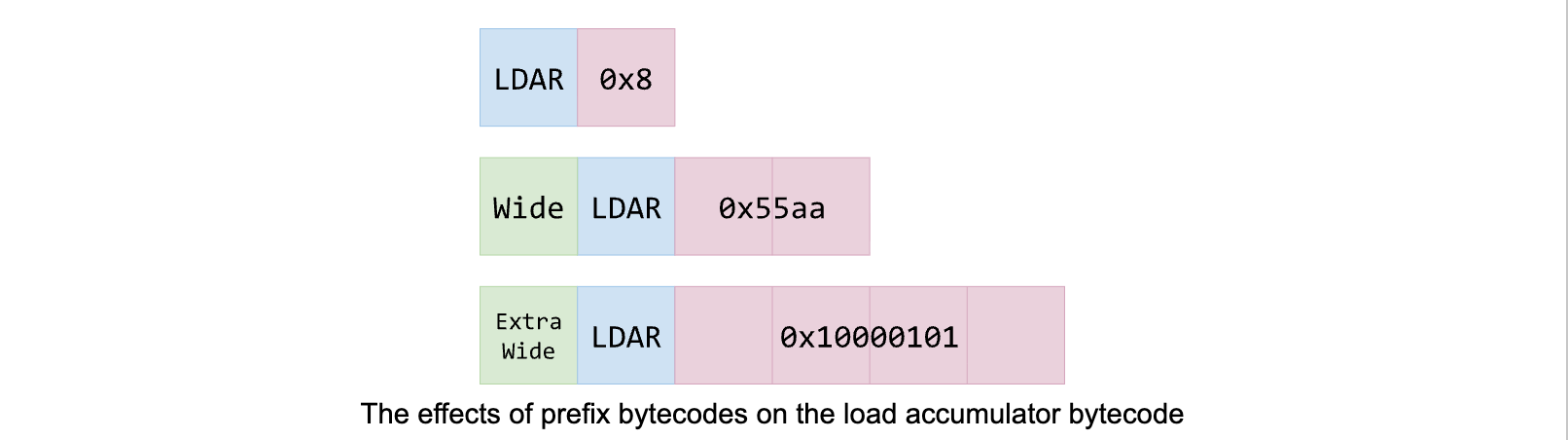
加载累加器
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| LdaZero | 0x02 | Acc=0 |
|
| LdaSmi | 0x03 | [imm] | Acc=[imm] |
| LdaUndefined | 0x04 | Acc=undefined |
|
| LdaNull | 0x05 | Acc=null |
|
| LdaTheHole | 0x06 | Acc=<The Hole> |
|
| LdaTrue | 0x07 | Acc=true |
|
| LdaFalse | 0x08 | Acc=false |
|
| LdaConstant | 0x09 | [idx] | 常量池第[idx]个常量到Acc |
解释下两个东西:
1.Smi:小整数是一种优化手段,JS的变量里能放任何类型,正常来讲它就应该放在堆上,但是如果一些小的数字也放堆上会造成大的内存和性能的开销,于是v8采用了带标签的指针(Tagged Pointers)来存储指针和数字,因为指针是有对齐的,所以最低位不会使用,就可以用最低位来标记它是数字还是指针(指向堆上的对象),它的真实值要右移才能得到
2.The Hole,它是V8的一个内部特殊值,表示空缺/未初始化状态,而且比undefined还要空;比如在作用域有个`let a=1,那么在执行到它之前,a的值就是The Hole,访问它会抛ReferenceError
二元操作
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| Add | 0x2b | [reg] | Acc=Acc+[reg] |
| Sub | 0x2c | [reg] | Acc=Acc-[reg] |
| Mul | 0x2d | [reg] | Acc=Acc*[reg] |
| Div | 0x2e | [reg] | Acc=Acc/[reg] |
| Mod | 0x2f | [reg] | Acc=Acc%[reg] |
| BitwiseOr | 0x30 | [reg] | Acc=Acc||[reg] |
| BitwiseXor | 0x31 | [reg] | Acc=Acc^[reg] |
| BitwiseAnd | 0x32 | [reg] | Acc=Acc&[reg] |
| ShiftLeft | 0x33 | [reg] | Acc=Acc<<[reg] |
| ShiftRight | 0x34 | [reg] | Acc=Acc>>[reg] (有符号右移) |
| ShiftRightLogical | 0x35 | [reg] | Acc=Acc>>>[reg] (无符号右移) |
| AddSmi | 0x36 | [imm] | Acc=Acc+imm |
| SubSmi | 0x37 | [imm] | 同理 |
| MulSmi | 0x38 | [imm] | |
| DivSmi | 0x39 | [imm] | |
| ModSmi | 0x3a | [imm] | |
| BitwiseOrSmi | 0x3b | [imm] | |
| BitwiseXorSmi | 0x3c | [imm] | |
| BitwiseAndSmi | 0x3d | [imm] | |
| ShiftLeftSmi | 0x3e | [imm] | |
| ShiftRightSmi | 0x3f | [imm] | |
| ShiftRightLogicalSmi | 0x40 | [imm] |
闭包分配
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| CreateClosure | 0x6e | [id],[imm] | 在函数内部定义另一个函数时,会为这个内部函数生成该指令,它的参数1表示函数的SharedFunctionInfo id,参数2为分配标志位,如是否预固化;它会创建一个JSFunction,它的上下文指针会指向函数定义所在的执行上下文,新创建的函数会存入Acc |
Global操作
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| LdaGlobal | 0x0a | [idx] | Acc=global[idx],如果不存在会抛ReferenceError |
| LdaGlobalInsideTypeof | 0x0b | [idx] | Acc=typeof global[idx] |
| StaGlobalSloppy | 0x0c | [idx] | 宽松模式,global[idx]=Acc,不存在会隐式新建 |
| StaGlobalStrict | 0x0d | [idx] | 严格模式,global[idx]=Acc,不存在会抛ReferenceError |
一元操作
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| Inc | 0x41 | Acc++ |
|
| Dec | 0x42 | Acc-- |
|
| ToBooleanLogicNot | 0x43 | Acc=!Acc,它会先转换为布尔值再取反 |
|
| LogicalNot | 0x44 | Acc=!Acc |
|
| TypeOf | 0x45 | Acc=typeof Acc |
|
| DeletePropertyStrict | 0x46 | [reg],[reg] | 严格模式Acc=delete reg0[reg1],删除non-configurable属性抛TypeError |
| DeletePropertySloppy | 0x47 | [reg],[reg] | 宽松模式Acc=delete reg0[reg1],删除失败不抛异常,只返回false |
Call操作
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| GetSuperConstructor | 0x48 | [this_function_reg] | 在子类的构造函数中,当前的构造函数作为输入,去查找父类的构造函数,存于ACC |
| CallAAnyReceiver | 0x49 | [callable_reg], [first_arg_reg], [arg_count] | 是一条通用的函数调用指令,它的特点是接收者(this 的值)是动态的。在执行这条指令前,调用者需要将 this的值、函数本身、以及所有参数都按顺序准备好在寄存器中,它会使用这些准备好的值来完成一次函数调用 |
| CallProperty | 0x4a | [callable_reg], [receiver_reg], [arg_count] | 调用对象的方法,这是通用版本,接受任意多个参数 |
| CallProperty0 | 0x4b | [callable_reg], [receiver_reg], [arg_N_reg] | 接下来这三个是优化版本,分别接受0 1 2个参数 |
| CallProperty1 | 0x4c | [callable_reg], [receiver_reg], [arg_N_reg] | |
| CallProperty2 | 0x4d | [callable_reg], [receiver_reg], [arg_N_reg] | |
| CallUndefinedReceiver | 0x4e | [callable_reg], [arg_count] | 调用普通的函数,其它方面同上 |
| CallUndefinedReceiver0 | 0x4f | [callable_reg], [arg_N_reg] | |
| CallUndefinedReceiver1 | 0x50 | [callable_reg], [arg_N_reg] | |
| CallUndefinedReceiver2 | 0x51 | [callable_reg], [arg_N_reg] | |
| CallWithSpread | 0x52 | [callable_reg], [arg_count] | 调用有剩余参数(含展开语法Spread Syntax)的函数,它的最后一个参数是可迭代对象,它会将这个可迭代对象展开,将其中的元素和前面的普通参数合并成一个完整的参数列表 |
| CallRuntime | 0x53 | [idx],[imm] | 调用 V8 引擎内部用 C++ 编写的运行时函数,它会从解释器赚到本地运行时执行;参数为内部函数id和参数个数 |
| CallRuntimeForPair | 0x54 | [id],[imm] | 类似CallRuntime,但是返回一对值 |
| CallJsRuntime | 0x55 | [reg],[id],[imm] | 调用 V8 引擎内部用 JS 编写的运行时函数( "Builtin");参数分别为js内置函数所需上下文,函数id和参数个数 |
| InvokeIntrinsic | 0x56 | [id] | 执行一个Intrinsic函数,Intrinsic 是指那些极其常用、性能要求极高的底层操作 |
| Construct | 0x57 | [constructor_reg], [first_arg_reg], [arg_count] | 调用构造函数 |
| ConstructWithSpread | 0x58 | 调用有剩余参数的构造函数 |
上下文分配
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| CreateBlockContext | 0x6f | [scope_info] | 它创建一个上下文对象,专门用来存放这些块级作用域的变量,以确保即使在代码块执行完毕后,内部的闭包依然能够访问到它们。如果块内的变量没有被闭包捕获,V8会进行优化,可能直接将它们分配在栈上,而无需创建上下文;scope_info指向一个描述该作用域信息的对象,告诉 V8 这个上下文需要为哪些变量预留空间 |
| CreateCatchContext | 0x70 | [exception_reg], [scope_info] | catch 块中捕获到的异常变量(如 e)的作用域仅限于该 catch 块内部。这条指令会创建一个特殊的上下文,并将 [exception_reg] 寄存器中的异常对象存入其中。这使得 e成为一个块级作用域的变量,并且如果 catch 块内有闭包捕获了 e,也能保证其能被正确访问 |
| CreateFunctionContext | 0x71 | [scope_info] | 创建一个上下文对象,用于“收养”这些被内部函数“闭包”了的父函数局部变量。这样,即使父函数已经执行完毕返回了,这些变量依然存活在堆上的这个上下文中,可供子函数在未来的任何时候访问 |
| CreateEvalContext | 0x72 | [scope_info] | eval() 的行为非常动态,它执行的字符串代码可以声明新的变量,并可能影响其所在的外部作用域。为了正确处理这种动态性,V8 会为 eval()的执行创建一个专属的上下文,这个上下文连接着调用 eval() 时的作用域链,使得 eval() 内部的代码能够正确地进行变量查找和声明 |
| CreateWithContext | 0x73 | [object_reg], [scope_info] | with 语句会将其指定的对象(位于 [object_reg])动态地添加到作用域链的最前端。这条指令就是通过创建一个特殊的“with 上下文”来实现这一点的,这个上下文内部持有着 obj 的引用,当在 with 块内部查找变量时,引擎会首先在这个“with 上下文”中查找,这相当于在 obj 的属性中查找,如果找不到再沿着正常的作用域链继续向上查找 |
测试/比较运算
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| TestEqual | 0x59 | [reg] | Acc=Acc==[reg] |
| TestEqualStrict | 0x5a | [reg] | Acc=Acc===[reg] |
| TestLessThan | 0x5b | [reg] | Acc=Acc<[reg] |
| TestGreaterThan | 0x5c | [reg] | Acc=Acc>[reg] |
| TestLessThanOrEqual | 0x5d | [reg] | Acc=Acc<=[reg] |
| TestGreaterThanOrEqual | 0x5e | [reg] | Acc=Acc>=[reg] |
| TestEqualStrictNoFeedback | 0x5f | [reg] | Acc=Acc===[reg],上面的比较会收集比较值的类型信息,这一条不会 |
| TestInstanceOf | 0x60 | [reg] | Acc=Acc instanceof [reg] |
| TestIn | 0x61 | [reg] | Acc=Acc in [reg] |
| TestUndetectable | 0x62 | 为了处理一些历史遗留问题,来检测ACC的值是否是不可检测的(Undetectable)对象 | |
| TestNull | 0x63 | Acc=Acc===null |
|
| TestUndefined | 0x64 | Acc=Acc===undefined |
|
| TestTypeOf | 0x65 | [type_flag] | 它直接将累加器中值的类型与一个立即数类型标志 [type_flag] 进行比较,效率高 |
注:不严格比较会做类型转换,而严格比较是类型和值都相等才行
上下文操作
上面已经讲了上下文(Context),当一个函数内部的变量需要被其嵌套的子函数(即闭包)访问时,这个变量就不能简单地存储在当前函数的栈帧上(因为函数执行完毕后栈帧会被销毁)。取而代之,V8 会在堆上创建一个 Context 对象来存储这些“逃逸”的变量,Context 对象通过链表连接起来,形成作用域链,由于是静态作用域它能在编译时确定所以有了很多直接槽访问指令,但有些要运行时才确定(如eval中执行的)所以也有查找指令:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| PushContext | 0x0e | [reg] | 当进入一个新的作用域时,它将[reg]中的新上下文对象推入上下文链顶部,它就是新的当前上下文 |
| PopContext | 0x0f | PushContext的逆操作 |
|
| LdaContextSlot | 0x10 | [context_reg], [slot_index], [depth] | 从指定的上下文中读取变量到累加器,depth 指示了要向上追溯多少层上下文链(0 代表当前),slot_index 指示了变量在那个上下文对象中的具体位置 |
| LdaImmutableContextSlot | 0x11 | [context_reg], [slot_index], [depth] | 用于加载不可变(Immutable)变量的超级优化版本,主要用于加载由 const 声明的变量,因为它加载的值是保证不会改变的,所以 TurboFan可以进行非常激进的优化,例如将这个值当作编译期常量来直接使用,从而可能消除大量的计算和分支 |
| LdaCurrentContextSlot | 0x12 | [slot_index] | 这是 LdaContextSlot 的一个优化版本,当要访问的变量位于当前上下文(即 depth 为 0)时,V8 会使用这条更短、更快的指令,它只需要一个操作数来指定槽位索引 |
| LdaImmutableCurrentContextSlot | 0x13 | [slot_index] | - |
| StaContextSlot | 0x14 | [context_reg], [slot_index], [depth] | 将累加器中的值写入到指定的上下文槽位中 |
| StaCurrentContextSlot | 0x15 | [slot_index] | StaContextSlot 的优化版本,用于将累加器中的值写入当前上下文的指定槽位 |
| LdaLookupSlot | 0x16 | [name_index] | 它会执行一次完整的动态作用域链查找,从当前作用域开始,逐级向上(包括所有上下文、with 对象等),一直查找到全局作用域,去寻找由 [name_index]指定的变量,一旦找到,就加载其值到累加器并停止查找,如果到最后都没找到,会抛出 ReferenceError |
| LdaLookupContextSlot | 0x17 | [name_index] | 只在上下文找,到全局作用域之前停止 |
| LdaLookupGlobalSlot | 0x18 | [name_index] | 在全局作用域找 |
| LdaLookupSlotInsideTypeof | 0x19 | 接下来三条都是typeof的特化版本,注意typeof找不到结果是undefined | |
| LdaLookupContextSlotInsideTypeof | 0x1a | - | |
| LdaLookupGlobalSlotInsideTypeof | 0x1b | - | |
| StaLookupSlot | 0x1c | [name_index] | - |
类型转换
下面三个是根据 ECMAScript 规范中定义的内部转换规则,将累加器中的值显式地转换为另一种类型,具体每种类型的值怎么转换要查文档:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| ToName | 0x66 | Acc=toName(Acc)根据真实类型按特定的方法转换为属性名类型(如string/Symbol) |
|
| ToNumber | 0x67 | Acc=toNumber(Acc)根据真实类型按特定方法转换为number,如true->1,'123'->123,'a'->Nan等 |
|
| ToObject | 0x68 | Acc=toObject(Acc)根据真实类型按特定方法转换为object,本身是对象就不变,null/undefined会抛TypeError,其他的string/number/symbol等会装箱 |
参数分配
下面的指令处理两类东西,隐式的arguments和ES6的剩余参数(...args):
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| CreateMappedArguments | 0x74 | Acc=created arguments在宽松模式下且不包含复杂参数时,创建的arguments和命名参数是双向绑定的,改其中一个另一个也会被修改 |
|
| CreateUnmappedArguments | 0x75 | Acc=created arguments在严格模式或包含复杂参数时,创建的arguments是原始参数的快照,他们不会相互影响 |
|
| CreateRestParameter | 0x76 | Acc=created rest将所有未被捕获的(剩余)参数放到一个真正的数组中,再将结果放到acc便于之后放到对应的变量 |
注:存在三种复杂参数,这些都会导致双向映射复杂容易出奇异:
1.默认参数:
function foo(a=1,b=2)2.剩余参数:
function foo(a,..b)3.解构参数:
function foo({a=1,b=2})
寄存器传输
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| Ldar | 0x1d | [reg] | Acc=[reg] |
| Star | 0x1e | [reg] | [reg]=Acc |
| Mov | 0x1f | [reg1],[reg2] | [reg2]=[reg1] |
控制流
先说下Jump指令的模式:
1.条件跳转:JumpIfxxx都是根据Acc决定是否要跳转
2.远跳转:xxxConstant是使用常量池里的值作为偏移跳转,用于远跳转,而短跳转便宜直接作为指令的操作数了
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| JumpLoop | 0x77 | [offset] | 它专用于跳到循环开头,专门的指令是为了做循环优化,例如栈上替换(On-Stack Replacement, OSR)在执行时发现它非常热就直接跳到JIT去执行,或者作为一个中断点 |
| Jump | 0x78 | [offset] | pc+=offset无条件近跳转 |
| JumpConstant | 0x79 | [idx] | pc+=constantpool[idx]无条件远逃转 |
| JumpIfTrue | 0x85 | [offset] | Acc严格等于True再跳 |
| JumpIfTrueConstant | 0x7e | [idx] | - |
| JumpIfFalse | 0x86 | [offset] | - |
| JumpIfFalseConstant | 0x7f | [idx] | - |
| JumpIfToBooleanTrue | 0x83 | [offset] | Acc先转换为布尔值再比较为True再跳 |
| JumpIfToBooleanTrueConstant | 0x81 | [idx] | - |
| JumplfToBooleanFalse | 0x84 | [offset] | - |
| JumplfToBooleanFalseConstant | 0x82 | [idx] | - |
| JumplfNull | 0x87 | [offset] | Acc严格等于null再跳 |
| JumplfNotNull | 0x88 | [offset] | |
| JumplfNullConstant | 0x7a | [idx] | - |
| JumplfNotNullConstant | 0x7b | [idx] | |
| JumplfUndefined | 0x89 | [offset] | Acc严格等于undefined再跳 |
| JumplfNotUndefined | 0x8a | [offset] | |
| JumplfUndefinedConstant | 0x7c | [idx] | |
| JumplfNotUndefinedConstant | 0x7d | [idx] | - |
| JumpIfJSReceiverConstant | 0x80 | [idx] | 这是一条内部类型检查指令,在 V8 的类型系统中,JSReceiver 是所有可以拥有属性的对象类型的基类(包括普通对象、数组、函数等,但不包括null)。这条指令检查累加器中的值是否是一个 JSReceiver,如果是,则执行跳转,常用于在执行属性访问等操作前,判断操作目标是否为一个合法对象 |
| JumpIfJSReceiver | 0x8b | [offset] | |
| SwitchOnSmiNoFeedback | 0x8c | [table_const_index], [case_range] | 这是switch的高效实现,专门针对条件变量是smi的情况,它利用跳转表和case范围来直接跳转而不用执行大量if判断,而且它没有类型反馈 |
非局部控制流
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| Throw | 0x93 | 将Acc中的值作为异常抛出,它会立即停止当前域的执行并向上传播异常直到找到一个能处理它的catch或程序终止 | |
| ReThrow | 0x94 | 在catch中重新抛出异常,它会保留异常对象的原始堆栈追踪 | |
| Return | 0x95 | 返回Acc到上层 | |
| ThrowReferenceErrorIfHole | 0x96 | [reg] | 用来实现暂时性死区(Temporal Dead Zone, TDZ)的,在代码执行到变量的实际声明行之前,任何对该变量的访问都会先触发这条指令,它检查如果还是TheHole就抛异常 |
| ThrowSuperNotCalledIfHole | 0x97 | 它确保在 ES6 的派生类(子类)的构造函数中,this 被访问前 super() 已经被调用 | |
| ThrowSuperAlreadyCalledIfNotHole | 0x98 | 它确保 super() 在一个构造函数中只被调用一次 |
字面量
字面量就是直接在代码中写的,比如[]/{}//.../等,它们分别对应三条指令:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| CreateRegExpLiteral | 0x69 | [pattern_idx], [flags_idx], [literal_idx] | 创建一个正则表达式的字面量,存于Acc |
| CreateArrayLiteral | 0x6a | [const_idx] | 创建一个数组字面量,const_idx指向常量池中的样板Boilerplate对象,返回存于Acc |
| CreateEmptyArrayLiteral | 0x6b | [const_idx] | 创建空列表 |
| CreateObjectLiteral | 0x6c | [const_idx] | 创建对象,用字面量创建对象性能会很好,因为V8能预先知道对象结构来生成高度优化的代码,返回同样存于Acc |
| CreateEmptyObjectLiteral | 0x6d | - |
属性操作
先说一个概念,内联缓存(Inline Caching, IC),当 V8 第一次执行属性访问时,它需要做很多工作来查找属性。IC机制会把这次查找的结果(例如对象的“形状”以及属性在内存中的偏移量)缓存起来,当代码第二次以相同的方式访问属性时,V8就可以直接使用缓存信息,跳过慢速查找,极大地提升了性能,下面的指令涉及的feedback_slot就是指向反馈向量的索引(槽位),Ignition会在这里记录本次属性访问的运行时信息,TurboFan会在后续利用这些信息生成高度优化的机器码:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| LdaNamedProperty | 0x20 | [object_reg], [name_idx], [feedback_slot] | Acc=[object_reg].constpool[name_idx],用点符号访问属性,属性名是编译时已知的 |
| LdaKeyedProperty | 0x21 | [object_reg], [feedback_slot] | Acc=[object_reg][Acc],用方括号访问属性,属性名要动态计算 |
| LdaModuleVariable | 0x22 | [cell_index], [depth] | ES6 模块环境中加载一个变量的值 |
| StaModuleVariable | 0x23 | [cell_index], [depth] | 修改当前模块中声明的顶层变量,改导入的会抛TypeError |
| StaNamedPropertySlopy | 0x24 | [object_reg], [name_index], [feedback_slot] | 命名属性赋值 |
| StaNamedPropertyStrict | 0x25 | [object_reg], [name_index], [feedback_slot] | - |
| StaNamedOwnProperty | 0x26 | [object_reg], [name_index], [feedback_slot] | 定义对象自生的新属性,它不会检查原型链速度比StaNamedPropertyxx更快 |
| StaKeyedPropertySlopy | 0x27 | [object_reg], [key_reg], [feedback_slot] | 键控属性赋值 |
| StaKeyedPropertyStrict | 0x28 | [object_reg], [key_reg], [feedback_slot] | - |
| StaDataPropertyInLiteral | 0x29 | [object_reg], [key_reg_or_name_idx], [flags] | 专用于对象/数组字面量的初始化过程,会做赋值和属性设置 |
| CollectTypeProfile | 0x2a | [feedback_slot] | 和IncBlockCounter类似,但它收集类型信息 |
复杂控制流
for-in是js中特殊的迭代方式,它会迭代对象中所有可枚举对象,包括本身和原型链的,所以分了下面的几条指令:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| ForInPrepare | 0x8d | [object_reg], [result_regs] | 准备阶段,object_reg中是待迭代的对象,它返回一个状态对象,包括键列表,迭代对象等信息 |
| ForInContinue | 0x8e | 循环继续 | |
| ForInNext | 0x8f | [state_regs], [index_reg] | 在每次循环开始时执行,获取下一个要迭代的属性键存于Acc |
| ForInStep | 0x90 | [index_reg] | 在循环末尾执行,递增循环索引 |
注:尽管看着类似,但
for-of底层是完全不同的,它处理的是标准化的数据,遵循迭代器协议,用前面的普通控制流就可以处理,所以没有专门的指令!
生成器
先说说异步,N年前JS有回调地狱,后来Promise出现一定程度解决了它,但是它依然不直观,后来又有了await/async来用同步的方式写异步的代码,不过JS中的await只是语法糖,它的底层还是Promise和生成器结合,JS的生成器好像很少用?但是语法和Python差不多,生成器用到的就是下面两条指令:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| ResumeGeneratorState | 0x99 | [generator_reg] | 当外部调用.next(x)去获取生成器的下一个值时,又会恢复生成器原来保存的状态信息,控制权切回生成器代码,并将外部值传给a=yeild |
| SuspendGenerator | 0x9a | [generator_reg] | 当yeild x时,会使用该指令,它将当前函数的完整状态(各种寄存器值)全部保存在生成器对象里,然后将x给Acc后返回外部生成器.next的调用者,就是说当前函数被冻结,控制权主动交给外部 |
| ResumeGeneratorRegisters | 0x9b | [generator_reg] | - |
断点
先说下V8里断点的实现机制,当设置一个断点时,调试器并不是直接在原始的字节码上进行修改。相反,它首先会复制一份当前函数完整的 BytecodeArray(字节码数组)对象,然后调试器会在这个副本上,找到断点所在位置对应的字节码,并将其替换为一条特殊的 DebugBreak 指令。
由于字节码是变长指令,为了保证字节码数组的结构完整性,V8必须使用一个与原始指令占用空间完全相同的 DebugBreak 变体来进行替换,所以根据原始指令长度不同它有9个变体,再加上我们在js里用的debuger;共10条:
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| Debugger | 0x9c | debugger指令 | |
| DebugBreak0 | 0x9d | 替换无参指令 | |
| DebugBreak1 | 0x9e | [arg1] | 1个参数的指令 |
| DebugBreak2 | 0x9f | [arg1],[arg2] | ... |
| DebugBreak3 | 0xa0 | [arg1],[arg2],[arg3] | ... |
| DebugBreak4 | 0xa1 | [arg1],[arg2],[arg3],[arg4] | ... |
| DebugBreak5 | 0xa2 | [id],[arg1],[arg2] | ... |
| DebugBreak6 | 0xa3 | [id],[arg1],[arg2],[arg3] | ... |
| DebugBreakWide | 0xa4 | ... | |
| DebugBreakExtraWide | 0xa5 | ... |
其它
| 助记符 | 操作码 | 操作数 | 说明 |
|---|---|---|---|
| StackCheck | 0x91 | 检查栈大小是否还充足,通常被插入在函数入口处,如果不足会抛RangeError | |
| SetPendingMessage | 0x92 | 在异常被抛出时,会栈展开去找能处理的catch handler,每展开一层内层会被销毁,所以用该指令将Acc里的e放在带处理消息/异常的槽位中 | |
| IncBlockCounter | 0xa6 | 内部用来做性能分析的,通常会插在基本块入口记录执行次数 | |
| Illegal | 0xa7 | 非法指令,用来捕获严重错误的,遇到会崩溃 |
Ghidra Sleigh

清楚V8的字节码了,它的ISA是基于寄存器的,所以可以很方便的利用现有框架做反编译,只需要将V8 ByteCode转换为框架所需IR即可,PT SWARM的研究者们选择了Ghidra,现在先根据其官方文档[11],来详细记录其语法。
Ghidra的优点是完全开源,不像ida SDK文档都不全,微码更是遮遮掩掩的,要扩展Ghidra来新增V8快照处理只需要用到Sleigh,它源于SLED(一种架构无关的ISA),能完整描述新的VM,利用它可以解析任何格式,将任意字节码显示为汇编形式,并且它也描述字节码到P-Code的翻译,Ghidra的反编译等分析是基于Ghidra的,所以通过Sleigh可以实现完整的反编译分析!
文件说明
先简单说明下各种文件,详细可以看源码样例:
.slaspec (Sleigh Specification)
Sleigh 规范文件是最核心的源文件。下面要讨论的所有Sleigh代码,比如define token, define register, attach, with,以及指令的构造器和表,全部都写在这个文件里。它用Sleigh语言完整地描述了一个CPU的指令集架构。它是纯文本格式,作为Sleigh编译器(sleigh.exe)的主要输入,它可以通过@include指令包含一个或多个.sinc文件。
.sinc (Sleigh Include)
Sleigh 包含文件类似于C语言中的头文件(.h)。当.slaspec文件变得非常庞大时,您可以用.sinc文件来组织和拆分代码,以提高可维护性。例如,您可以把所有寄存器的定义放在registers.sinc中,把所有寻址模式的定义放在addrmodes.sinc中。它的格式与.slaspec文件完全相同,都是纯文本的Sleigh代码,并被主.slaspec文件通过@include "registers.sinc"这样的指令包含进去。在编译时,它会被当作是.slaspec文件的一部分。
.sla (Sleigh Language Artifact)
Sleigh 语言产物(或编译后文件)是.slaspec文件编译后的产物。.slaspec是人类可读的源码,而.sla是经过Sleigh编译器优化的、Ghidra在运行时可以直接使用的二进制文件。Ghidra的反汇编引擎为了追求极高的解码速度,直接读取的是这个文件,而不是.slaspec源码。所以它是二进制格式,是Sleigh编译器(sleigh.exe)的输出。Ghidra在进行反汇编分析时,依赖的是这个文件。
.cspec (Compiler Specification)
编译器规范文件,它对于反编译器(Decompiler)至关重要,它描述的不是CPU本身,而是编译器如何为这个CPU生成代码,即应用程序二进制接口(ABI)。如果说.sla文件告诉Ghidra“这条指令是什么”,那么.cspec文件则告诉Ghidra“C语言中的函数调用、参数传递等是如何用这些指令实现的”。它包含: * 函数调用约定: __cdecl, __stdcall等。参数是通过寄存器还是堆栈传递?谁负责清理堆栈? * 数据类型模型: int, long, pointer等类型的大小和对齐方式。 * 堆栈行为: 堆栈是向上增长还是向下增长,堆栈指针的用途等。
它与.sla文件协同工作,是Ghidra能够生成高质量C代码的关键。没有它,反编译结果会非常糟糕。
.pspec (Processor Specification)
处理器规范文件是一个“清单”或“元数据”文件,它将一个处理器模块的所有组成部分联系在一起。它是Ghidra识别一个新处理器的入口点。它是XML格式,述一个处理器的中心文件,其内容通常会指向: * 编译好的Sleigh文件 (.sla) * 编译器规范文件 (.cspec) * 以及其他信息,如处理器名字、字节序(endianness)、RAM默认地址空间等。
.ldefs (Language Definitions)
语言定义文件是Ghidra的“语言注册表”,它是一个XML文件,列出了Ghidra知道的所有处理器“语言”的ID和描述。当在Ghidra中导入一个新程序时,弹出的“Language”下拉选择框中的所有选项,都来自于这个文件。它是XML文件,是最顶层的索引文件。Ghidra启动时会读取它,以了解自己支持哪些处理器。文件中的每一个
.opinion (Opinion)
“意见”文件,这是一个辅助性的“推荐”文件,用于帮助Ghidra在导入一个二进制文件时,自动选择最合适的语言。它定义了一系列规则,例如“如果我看到了一个ELF格式的文件,并且它的e_machine头字段是EM_AARCH64,那么我强烈‘建议’(opinion)使用AARCH64:LE:64:v8这个语言ID”。它是XML格式,将二进制文件格式的特征与.ldefs文件中定义的语言ID关联起来,提升用户体验。
P-Code
先说P-Code,它是一种基于寄存器的中间表示,也可以说是转换语言,它能建模任何通用处理器,所以只需要为它实现静态分析(控制流/数据流及后续优化解混淆)与反编译,再实现各种ISA->P-Code的转换就可以实现各种类型的反编译,现在看看它的三个概念:
1.地址空间:包括RAM和寄存器等,可以有任意多个,后面会说怎么定义新的地址空间
2.VarNode:空间中连续的字节序列,它可以是任意空间的任意长度的序列,它的含义依据所处上下文(通常是P-Code指令)而定,比如它会被解释为小端序的有符号整数,解释为浮点数等
3.操作:就是指令,通常一条要分析的机器指令会被多条P-Code指令来表示,这一组P-Code指令就是操作,它们默认顺序执行(除非有分支),并且有显式的输入输出(VarNode)
现在列出P-Code的所有操作(指令):
| Operation Category | List of Operations |
|---|---|
| Data Moving | COPY, LOAD, STORE |
| Arithmetic | INT_ADD, INT_SUB, INT_CARRY, INT_SCARRY, INT_SBORROW, INT_2COMP, INT_MULT, INT_DIV, INT_SDIV, INT_REM, INT_SREM |
| Logical | INT_NEGATE, INT_XOR, INT_AND, INT_OR, INT_LEFT, INT_RIGHT, INT_SRIGHT, POPCOUNT, LZCOUNT |
| Integer Comparison | INT_EQUAL, INT_NOTEQUAL, INT_SLESS, INT_SLESSEQUAL, INT_LESS, INT_LESSEQUAL |
| Boolean | BOOL_NEGATE, BOOL_XOR, BOOL_AND, BOOL_OR |
| Floating Point | FLOAT_ADD, FLOAT_SUB, FLOAT_MULT, FLOAT_DIV, FLOAT_NEG, FLOAT_ABS, FLOAT_SQRT, FLOAT_NAN |
| Floating Point Compare | FLOAT_EQUAL, FLOAT_NOTEQUAL, FLOAT_LESS, FLOAT_LESSEQUAL |
| Floating Point Conversion | INT2FLOAT, FLOAT2FLOAT, TRUNC, CEIL, FLOOR, ROUND |
| Branching | BRANCH, CBRANCH, BRANCHIND, CALL, CALLIND, RETURN |
| Extension/Truncation | INT_ZEXT, INT_SEXT, PIECE, SUBPIECE |
| Managed Code | CPOOLREF, NEW |
不过我们通常不用写P-Code,而是用Sleigh表达式,它是一种类似C语言的表达式,会被自动转换为P-Code:
| P-code Name | SLEIGH Syntax | Description |
|---|---|---|
COPY |
v0=v1 |
赋值操作 |
SUBPIECE |
v0:2/ v0(2) |
截断:varnode:size是截取varnode的最低size位,最高位如果有符号可能被截断;varnode(offset)是偏移offset之后的高位部分 |
POPCOUNT |
popcount(v0) |
位计算:v0中bit为1的个数 |
LZCOUNT |
lzcount(v0) |
前导零计算:v0前bit为0的个数 |
(simulated) |
v0[6,1] |
位提取:提取v0中指定位数,格式位[最低位,位数],如这里为第6位 (编号0开始) |
LOAD |
* v1/*[spc]v1/*:2 v1/*[spc]:2 v1 |
解引用/加载:可指定空间和大小,格式为*[space]:size varnode,不指定是默认空间,上下文指定的大小 |
STORE |
*v0 = v1/*[spc]v0 = v1;/*:4 v0 = v1;/*[spc]:4 v0 = v1 |
存储,同上 |
BOOL_NEGATE |
!v0 |
布尔非 |
INT_NEGATE |
~v0 |
按位取反 |
INT_2COMP |
-v0 |
取负(二进制补码) |
FLOAT_NEG |
f- v0 |
浮点数取负 |
INT_MULT |
v0 * v1 |
整数乘 |
INT_DIV |
v0 / v1 |
无符号整除 |
INT_SDIV |
v0 s/ v1 |
有符号整除 |
INT_REM |
v0 % v1 |
无符号模 |
INT_SREM |
v0 s% v1 |
有符号模 |
FLOAT_DIV |
v0 f/ v1 |
浮点数除 |
FLOAT_MULT |
v0 f* v1 |
浮点数乘 |
INT_ADD |
v0 + v1 |
整数加 |
INT_SUB |
v0 - v1 |
整数减 |
FLOAT_ADD |
v0 f+ v1 |
浮点数加 |
FLOAT_SUB |
v0 f- v1 |
浮点数减 |
INT_LEFT |
v0 << v1 |
左移 |
INT_RIGHT |
v0 >> v1 |
无符号(逻辑)右移,高位补0 |
INT_SRIGHT |
v0 s>> v1 |
有符号(算数)右移,高位符号位填充 |
INT_SLESS |
v0 s< v1/v1 s> v0 |
整数有符号小于 |
INT_SLESSEQUAL |
v0 s<= v1/v1 s>= v0 |
整数有符号小于等于 |
INT_LESS |
v0 < v1/v1 > v0 |
整数无符号小于 |
INT_LESSEQUAL |
v0 <= v1/v1 >= v0 |
整数无符号小于等于 |
FLOAT_LESS |
v0 f< v1/v1 f> v0 |
浮点数小于 |
FLOAT_LESSEQUAL |
v0 f<= v1/v1 f>= v0 |
浮点数小于等于 |
INT_EQUAL |
v0 == v1 |
整数等于 |
INT_NOTEQUAL |
v0 != v1 |
整数不等于 |
FLOAT_EQUAL |
v0 f== v1 |
浮点数等 |
FLOAT_NOTEQUAL |
v0 f!= v1 |
浮点数不等 |
INT_AND |
v0 & v1 |
按位与 |
INT_XOR |
v0 ^ v1 |
按位异或 |
INT_OR |
v0 | v1 |
按位或 |
BOOL_XOR |
v0 ^^ v1 |
布尔异或 |
BOOL_AND |
v0 && v1 |
布尔与 |
BOOL_OR |
v0 || v1 |
布尔或 |
INT_ZEXT |
zext(v0) |
零扩展,扩多少根据上下文的目标来 |
INT_SEXT |
sext(v0) |
符号扩展 |
INT_CARRY |
carry(v0,v1) |
无符号进位判断,v0和v1相加是否有进位 |
INT_SCARRY |
scarry(v0,v1) |
有符号进位/溢出判断,v0和v1相加是否产生符号溢出 |
INT_SBORROW |
sborrow(v0,v1) |
有符号借位判断,v0-v1是否产生有符号借位 |
FLOAT_NAN |
nan(v0) |
v0是否不是有效的浮点数 (not a number) |
FLOAT_ABS |
abs(v0) |
浮点数绝对值 |
FLOAT_SQRT |
sqrt(v0) |
浮点数平方根 |
INT2FLOAT |
int2float(v0) |
整数转浮点数 |
FLOAT2FLOAT |
float2float(v0) |
浮点数精度转换,根据目标长度,精度可能更高或更低 |
TRUNC |
trunc(v0) |
截断v0来获取有符号整数,v0应该是浮点数 |
FLOAT_CEIL |
ceil(v0) |
最接近但不小于v0的整数 |
FLOAT_FLOOR |
floor(v0) |
最接近但不大于v0的整数 |
FLOAT_ROUND |
round(v0) |
最接近v0的整数 |
CPOOLREF |
cpool(v0,...) |
从常量池访问值,下面会解释 |
NEW |
newobject(v0) |
分配一个类型为v0的对象 |
BRANCH |
goto v0; |
跳转到v0出执行 |
CBRANCH |
if (v0) goto v1; |
条件跳转 |
BRANCHIND |
goto [v0]; |
间接跳转,v0是当前地址空间的偏移 |
CALL |
call v0; |
函数调用,Ghidra就知道目标是个函数,在反编译时生成函数调用,也知道返回地址会入栈 |
CALLIND |
call [v0]; |
函数调用,跳转到v0存储的地址处 |
RETURN |
return [v0]; |
函数返回到v0所指地址,Ghidra就知道当前函数结束,反编译能生成return,而且能正确识别函数边界 |
*USER_DEFINED* |
define pcodeop ident;/a=ident(v0,...) |
上面表达不了的,可以自己定义宏/函数 |
注:
1.对于用户定义的操作,Ghidra并不知道它实际是如何操作数据的,他不会生成准确的P-Code而是生成一条标识用户定义P-Code的记录,只能分析他的输入输出数据,需用我们再用Java/CPP编写自定义分析器去处理它,见下面插件部分。
2.
newobject和cpool用于托管代码的操作,比如java/.net等语言,需要借助后端实现更复杂的功能,下面要说的插件就大量的使用了该功能3.
CALL其实和BRANCH一样,RETURN和CALLIND和BRANCHIND一样,都只是完成跳转,在函数调用时必须显式的计算返回地址并放在该有的位置(比如栈上),返回时也得显式指定地址,它们存在的目的只是给Ghidra提示
布局
1.注释:#表示注释,不过在构造函数的显示部分会有特殊含义,下面会提到
2.标识符:和C一样,数字大小写字母,下划线,多了个.,数字不能做开头
3.字符串:""之间为字符串
4.整数:0b表示二进制,0x表示十六进制,其它就是十进制,是否有符号或是否是小数根据上下文解析
4.空白:就是标准的/\t/\r/\v/\n
预处理
1.包含:@include "xx.slaspec",必须出现在行首
2.预处理宏:使用@define macro_name "xyz"定义宏(不能有参数),$(macro_name)展开宏,@undef macro_name删除宏定义
3.条件编译:和C一样,支持@ifdef/@ifndef/@if/@else/@elif/@endif来进行条件编译,其中@if的布尔表达式只能用于宏和字符串比较
基本定义
1.endian:sleigh规范必须首先定义字节序,当然字节序可在后续随时修改,例如define endian=big;
2.alignment:指令对齐,如果没对齐反汇编可以标记为错误,例如define alignment=2;
3.address space:前面简单提了下,可以定义任何多个地址空间,但通常只会有两个,寄存器和RAM,必须设置一个默认的空间,之后如果访存没指定空间则会访问它,下面说下他的语法:
define space spacename attributes ; # spacename 自己起,比如ram/register
# 下面是属性部分,实际通常还是写一行的
type=(ram_space|rom_space|register_space) # 空间类型,必须准确,比如rom不可写,register不可寻址
size=integer # 对于ram是地址指针大小,比如32位CPU此时应该是4,而register为寄存器最大宽度,32为也该为4
default # 默认空间则写上它
wordsize=integer # 一个地址单位对应多少字节,正常遇到的都是1字节
4.命名寄存器:通用寄存器可以命名,而且可以重叠,比如x86的ax是eax的低16位,它们实际是一个寄存器,这也能被处理,语法如下:
define spacename offset=integer size=integer stringlist ; # 这会定义很多varnodes,之后可以直接用名字访问
# 例如
define register offset=0 size=4 # 偏移从0开始,每个寄存器大小为4
[EAX ECX EDX EBX ESP EBP ESI EDI ];
define register offset=0 size=2 # 现在定义的偏移也为0,和上面的重叠了,但是大小为2,所以下面的两个对应上面一个
[AX _ CX _ DX _ BX _ SP _ BP _ SI _ DI]; # 这里编号会递增,如果那一位没有定义则用`_`表示跳过
define register offset=0 size=1
[AL AH _ _ CL CH _ _ DL DH _ _ BL BH ];
5.位寄存器:上面看到P-Code操作的最小单位是字节,但现实又确实存在位寄存器,比如状态寄存器,所以Sleigh提供了语法糖来定义它们,即先定义完整的容器寄存器,再定义该寄存器位范围的含义,其会被转换为移位和掩码操作(代价很大别乱用),语法如下:
define register offset=0x180 size=4 [ statusreg ]; # 先定义容器
define bitrange zf=statusreg[10,1] # 再定义每个位范围
cf=statusreg[11,1]
sf=statusreg[12,1];
6.用户定义操作:语法为define pcodeop arctan;
符号介绍
现在开始上强度,接触指令了,指令在二进制文件中就是一串数据,在静态分析中,它会被处理为两部分:
1.显示:就是反汇编,将它翻译为我们容易看懂的部分
2.语义:这是为了进一步反编译,也就是要把那段指令翻译为P-Code,Ghidra才能继续分析
这个过程是自底向上的,Sleigh中用符号(Symbol)来同时完成这两个任务,包括前面提到的ram/register/endian等都是符号,是最底层的最小单元的符号,也是具体符号,它会被一层一层组合,最终收缩到名为instruction的根符号,它是整个处理器指令集的总入口,现在简单描述下:
1.具体符号(Specific Symbol):比如define register ... [EAX],这个EAX就是具体符号,它在汇编里会显示为EAX而在语义层面又会是一个独特的varnode
2.家族符号(Family Symbol):它是将一组符号归类为一个家族,比如寄存器操作数(reg_operand),源操作数,目的操作数,在具体的上下文会是一个具体的符号
3.表(Table):它是语法规则,说明如何将符号组合成完整的指令,它可以层层嵌套,最上层的表为instruction,比如:
# :instruction is ... 表示定义一个名为 instruction 的表
:instruction is
MOV reg_dst, reg_src { reg_dst = reg_src; }
| ADD reg_dst, reg_src { reg_dst = reg_dst + reg_src; }
| ...
可能还有点抽象,下面会更详细描述相关语法,这里要先建立一个全局的视角!
说回符号,几乎所有的符号都在同一个全局空间,包括地址空间的名称,token、域、宏、表、寄存器、用户定义P-Code的名称等,所以不要重名会冲突,可以自己通过加前缀来分割命名空间;不过有个例外,就是构造器(就是指令描述,下面会详细说明)内的局部作用域可以有同名的符号,查找也是就近原则。最后,列出Sleigh的内置符号,能直接拿来用的:
| Identifier | Meaning |
|---|---|
instruction |
根指令表,Sleigh规范的顶层入口 |
const |
一个特殊的地址空间,来构造常量varnodes,很少直接用 |
unique |
另一个特殊地址空间,来构造临时varnodes,比如表达式写了(a+b)*c就会隐含的在unique里创建临时变量存中间结果,也可以用local定义临时变量 |
inst_start |
当前指令的起始偏移 |
inst_next |
下一条指令的起始偏移,比如函数调用时会用到 |
inst_next2 |
下下条指令的起始偏移,只在很特殊的场景用到 |
epsilon |
表示空比特模式,源于SLED,现在几乎用不到 |
Tokens和Fields
Token是指令中的一个解析单元,它是字节的整数倍大,一条指令由一个或多个token构成,通常定长指令是一个token,而变长指令会有多个;field是Token的内部切片,它将一个token划分为不同的部分,为不同比特范围命名便于后续使用它,语法如下:
define token tokenname ( integer ) # tokenname为token名称 integer为token大小,单位是bit,它一定是8的整数倍
fieldname=(integer,integer) attributelist # 每个域,注意这里是闭区间,比如(0,1)表示两位,属性有signed表示是否有符号会影响语义,hex/dex只用于显示
...
;
# 比如
define token instruction (32)
# 在这个32位的令牌内部定义字段
opcode = (26, 31)
dest_reg = (21, 25)
src_reg = (16, 20)
immediate = (0, 15)
;
注:它受字节序影响哦,大端和小端的(0,1)是原始数据的不同部位;另外field是可以重叠的!
现在field还是纯数字,上面的属性可以定义它的显示方式,但它还是数字,只适合立即数,且显示和语义是固定的,在实际的ISA中会出现数字表示寄存器编码,或语义/显示需要变化,于是引入attach语法,它有三种用法:
1.绑定为寄存器,此时显示和语义都会变化,例如反汇编会将0001显示为eax,并能在表达式中用eax参与计算,语法如下:
attach variables fieldlist registerlist; # field可以是一个或多个,寄存器也是`[]`的列表,从0开始编号,可用`_`占位跳过无效编号
# 例如,上面定义的源寄存器,可以被绑定
attach variables [ reg_field ] [ R0 R1 R2 R3 R4 R5 R6 R7 ]; 此时reg_field=0时,实际显示的就是R0
2.绑定为其它整数,此时显示不变,但是实际语义会发生变化,语法为:
attach values fieldlist integerlist; # 整数列表,不能用`_`占位哦
# 例如
attach values [ scale_field ] [ 1 2 4 8 ]; # 实际显示的还是 0 1 2 3,但在运算时会变成 1 2 4 8
3.绑定其它名称,此时语义不会变,只是反汇编的显示变了,语法为:
attach names fieldlist stringlist;
# 例如
attach names [ cond_field ] [ "EQ" "NE" "CS" "CC" ... ]; # 此时条件值为0,在p-code里运算也是0,但是会显示为EQ
其实从这里就看出了token/field是把具体符号抽象成了家族符号。
这里还要提一个,上下文变量(Context Variables),比如ARM处理器的ARM/Thumb模式,不同模式指令的含义是不同的,于是有了上下文变量来区分它们,语法为:
# 先定义容器,就是先把contextreg在寄存器空间里定义好
# 再定义上下文变量
define context contextreg
fieldname=(integer,integer) attributelist # 这就是上下文变量里的一个域了,属性除了支持signed/dec/hex外多了和noflow,默认全局设置上下文变量会影响从更改点开始的指令解码,向前,遵循指令流,但如果变量标记为noflow,则任何更改都限于单个指令
...
;
# 使用,比如Tbit是上下文变量里的一个域
:instruction is Tbit=1 & ... { # 这里是Thumb指令的解码规则 }
| Tbit=0 & ... { # 这里是ARM指令的解码规则 }
构造器
终于来到这,最核心最复杂的一块,构造器就是用来表示指令的,它分为五个部分,但实际通常写成一行:
1.表头:它指定了当前这条构造器规则是哪个表(Table)的一部分,它总是在一行的最开始,以表名和is关键字构成
2.显示部分:它定义了这条指令在反汇编中应该如何显示,这包括指令的助记符(mnemonic)以及操作数的顺序和格式,这是我们最终能看到的文本表示
3.比特模式部分:这是构造器的匹配条件,它精确地定义了输入的二进制指令需要满足什么样的比特模式,才能匹配到当前这条构造器规则,这是解码过程中最关键的判断依据
4.反汇编动作部分:这是一个可选的、高级的部分,通常用方括号 [...]括起来。前面我们已经学了attach,它能用固定映射来修改输出,但更复杂的海需要这一部分,反汇编动作允许编写一些复杂的只用于控制最终显示内容的逻辑(注意这些逻辑不属于P-Code语义)
5.语义动作部分:这是构造器的“心脏”,它描述了这条指令实际上做了什么,这部分代码是用花括号 {...} 括起来的P-Code,它会修改寄存器、内存等处理器的状态
例如下面就是一条构造器:
:Mov reg, imm is opcode=1®&imm [export imm] {reg=imm}
下面会详细说明每一部分
显示部分
它是:到is之间的部分,比如例子中的Mov reg, imm,它的显示规则是:
1.一个合法的(布局那有说怎样就是合法)标识符会被当成一个新的局部标识符,如果一个字面量是合法的标识符必须用""引起来才能原样输出,这里是申明,在后续会被定义/绑定,比如这里的reg/imm,关于定义/绑定后面会详细说
2.第一个标识符会被作为助记符,直接作为字面量输出,比如这里的Mov直接输出,助记符最好是唯一的
3.有个特殊字符^,它有两个特殊用法,第一种是不带空格的标识符拼接,比如有后缀的标识符,Jmp^cc中cc表示条件如GT,那么最后会被输出为JmpGT;第二种是当它出现在第一个标识符前面时,第一个标识符不会成为字面量而是解析其含义,比如有些指令有前缀,就要用它;例如有浮点FADD加和整数加IADD两条指令,那么应该写^prefix^ADD
4.对于空格,开头和结尾的空格会被删除,中间的多个空格会被合并为一个
5.剩下的部分,包括像()[]{},等特殊符号全都是字面量,字面量就是原样输出
比特模式
它是is到[/{(不存在反汇编动作时)之间的部分,来判断一个二进制数据是否匹配当前构造器,语法如下:
1.简单等式匹配,如上面的opcode=1,它只做原始数据匹配,会无视attach variables/attach values导致的变化
2.可使用&和|来组合约束,&优先级更高,而且更高效,可用()来调整优先级,它们只能用在同一个token上
3.可使用;来连接多个token,实现变长指令处理,;和&都表示逻辑与,除此之外它还多了一个顺序,即token1 ; token2时token1必须在token2的前面
4.变长指令还有个问题,就是对于长度不同的模式怎么处理,又多了个...,它能用于做右填充(A...)或左填充(...A)
5.匹配的东西不一定想显示出来,这个无所谓
6.它有个空模式,用epsilon来匹配任何模式
7.它还支持一个高级约束功能,直接判断符号和表达式关系(=/!=/>/<),比如在Xor EAX,EAX这种指令两个寄存器相等的场景可以简化为CLR EAX,但实际它是个语法糖会展开成(r1=0&r2=0)|(r1=1&r2=1)|...比较吃性能,所以非必要别用
8.最后,不仅是做匹配,它还支持局部标识的绑定,显示部分声明了局部标识reg/imm,在这里可以用® &imm直接将全局的同名标识符绑定过去,这会让它在显示和语义上都继承全局标识符,比如reg显示为EAX且语义也是EAX的varnode
注:匹配时,越精确的表达式优先级越高,如果出现相交但不包含的表达式,严格模式会报错,宽松模式会选择第一条,强烈不建议这种!
反汇编动作
它是可选的,存在时位于[]之间,比如一条相对跳转指令,我们想要它显示出跳转后的目标地址而不是偏移,就可以用它jmpdest: reloc is simm8 [ reloc=inst_next + simm8*4; ] { ... },它的输入是比特匹配的不可见标识符和内置标识符,输出是reloc,多条语句用;分割,下面列出模式表达式操作符:
| Operator Name | Syntax |
|---|---|
| Integer addition | + |
| Integer subtraction | - |
| Integer multiplication | * |
| Integer division | / |
| Left-shift | << |
| Arithmetic right-shift | >> |
| Bitwise and | $and& (within square brackets) |
| Bitwise or | $or| (within square brackets) |
| Bitwise xor | $xor^ |
| Bitwise negation | ~ |
注:
在
[]中位运算可用&/|/^或$and/$or/$xor,在比特模式中只能用后者,因为前者是逻辑运算!除了常规的运算,它还支持修改上下文变量,不过默认它只影响当前语句,之后的会恢复原始上下文变量,可以用
globalset语句来让它永久生效。
语义部分
就是{}中的部分,在静态分析中最重要出不得差错,它会被转换为P-Code,能用的表达式P-Code章节已经列了,只给些说明:
1.运算的输入和输出长度需要一致,除非用了扩展/截断等指令,如果无法根据上下文推断准确的大小,则需要手动指定否则会出错
2.有优先级,可以用()改变
3.&是取地址,它其实是反汇编时的常量替换,类似于宏,只能处理静态地址,比如register,获取它的偏移值
表达会被用来构成完整的句子(Statements),语句以;结尾,Sleigh支持多种类型的语句,下面给点说明:
1.语句的目标可以是作用域内可见的标识符,也可以是新的(默认会成为临时变量),但临时变量最好用local标记,临时变量可以先声明后使用,但声明时需要指定大小
2.子表可以使用export去导出值,它类似return返回值,该语句必须是最后一句切只能导出符号,比如在后增量寻址中:
mode: reg++ is addrmode=0x2 & reg { tmp=reg; reg=reg+1; export tmp; } # 返回了原始值,切reg会自增
LOAD dest, mode # 在这里用了子表,它的值就是export的tmp
除了export varnode,还可以用export *addr,它们都是导出引用,特别后者容易让人误解,它是导出那个位置本身而非其内容。
3.它支持类似C的goto和标签来做跳转,用来模拟一些特殊指令,比如内存拷贝,标签用<>括起来,比如:
:sum r1,r2,r3 is opcode=7 & r1 & r2 & r3 {
tmp:4 = 0;
r1 = 0;
<loopstart> # 定义标签
r1 = r1 + *r2;
r2 = r2 + 4;
tmp = tmp + 1;
if (tmp < r3) goto <loopstart>; # 跳转到标签
}
4.unimpl可表示未实现的语义,在反汇编时它能正确的显示出来,但是做进一步分析会报错
表
现在到表了,单个构造器是不会形成新的可复用的符号的,它只是一个匿名的规则,最后还是要用构造器隶属的表来,它是构造器规则的集合,可以被其它地方使用,表通常嵌套来表示复杂指令,现在可以用个例子:
`and r3, r5` (寄存器模式)
* 二进制编码: op=0x10, reg1=3, mode=0, reg2=5 -> 010000 0000 011 101 -> `0x406D`
* 解析树:
1. `instruction` (根): op=0x10 -> 匹配 :and reg1,op2 构造器
2. `and`的子节点:
* `reg1`: 字段值为3 -> attach后解析为具体符号 `r3`
* `op2` (子表): mode字段为0 -> 匹配 :op2: reg2 构造器
* `reg2`的子节点:
* `reg2`: 字段值为5 -> attach后解析为具体符号 `r5`
最终遍历符号树得到:
- 生成反汇编: 遍历树的“显示”部分,组合出字符串 "and r3, r5"
- 生成P-Code: 遍历树的“语义”部分,执行reg1 = reg1 & op2,其中reg1是r3,op2是op2子树导出的r5
其它
宏
它是编译时展开的,用于消除重复代码等,语法为:
macro macro_name(arg1,arg2...){
# body
}
它能用在除build外的位置
with块
with块同样用于消除重复代码,类似宏,比如:
# 原始代码存在相同的模式并大量重复
:ALU_ops: ADD dest,src is opcode=0x1A & func=0 { ... }
:ALU_ops: SUB dest,src is opcode=0x1A & func=1 { ... }
:ALU_ops: AND dest,src is opcode=0x1A & func=2 { ... }
# 用with将重复的模式提出来
with :ALU_ops: opcode=0x1A {
: ADD dest,src is func=0 { ... }
: SUB dest,src is func=1 { ... }
: AND dest,src is func=2 { ... }
}
with块会组合到每个部分的前面,比如比特模式或反汇编动作部分之前,所以如果内部改了同一个标识符则内部的会覆盖with块的。
build
上面提到的表达式生成P-Code完全是自动的,我们没法控制它的顺序,这在部分场景下可能出问题,此时可用build op1来强制立即在当前位置生成操作数op1对应的全部P-Code再执行后续语句,例如:
# 如果condition=1,则检查flag,若flag=1,就跳转到下一条指令,实现“跳过”
cc: "c" is condition=1 { if (flag==1) goto inst_next; }
# 如果condition=0,则什么也不做
cc: is condition=0 { }
## cc这个子表定义了一个操作数,它本身就包含了一个分支逻辑(副作用)
## 在`and`指令中使用`cc`并控制顺序
:and^cc r1,r2 is opcode=0x67 & cc & r1 & r2 {
build cc; # 如果没有这句,那么cc可能在r1 = r1 & r2执行,导致flag为1时错误的执行了代码
r1 = r1 & r2;
}
延迟槽
对于一些流水线架构的CPU,若存在延迟槽,如在执行分支指令时预取了下一条指令并在跳转前就执行了,为了模拟这种行为,有了delayslot(n),这里的n表示预取几条,它会取下面n条插入当前位置,如:
:beq r1,r2,dest is op=0xbc & r1 & r2 & dest {
flag=(r1==r2); # 先计算条件,是否要条件
delayslot(1); # 执行下一条指令
if flag goto dest; # 再跳转
}
项目分析
插件的源码在github:ghidra_nodejs,铺垫了那么多,终于到看源码的环节了~简单说下它实现的功能:
1.快照文件解析:快照是一个私有格式的二进制文件,需要编写elf/pe这种解析器来读取它的代码和数据(如常量池,上下文变量等)
2.基础指令解析:包括显示部分和语义部分,以便使用它的反编译,交叉引用等功能
3.P-Code注入模块:v8有很多指令是无法用静态的Sleigh表示的,于是要用到上面提到的define pcodeop操作,它会定义各种复杂操作,并由额外的Java模块解析它们,并生成更合适的P-Code代码[9]:
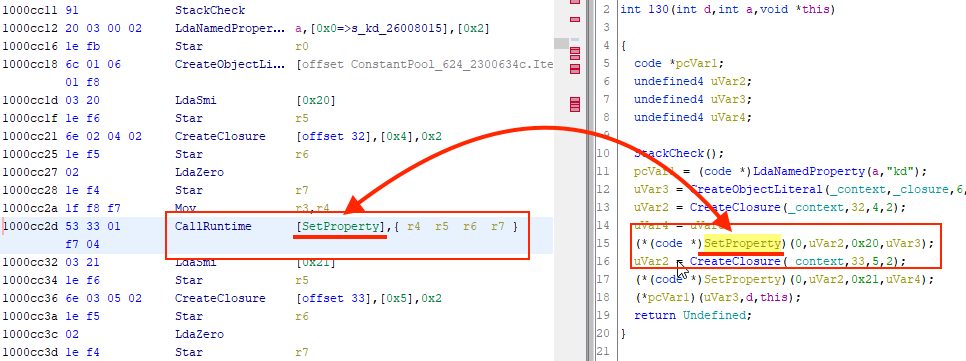
好了,可以自己去读代码了🤪
胡言乱语:俺觉得这是一个极佳的学习案例,但可能并不是最好的实践案例
参考
[1] JavaScript Bytecode – v8 Ignition Instructions
[2] learning-v8
[3] v8源码分析
[4] V8 Snapshot / Nw.js Source Protection 研究笔记
[6] Protect JavaScript source code with v8 snapshot
[7] How we bypassed bytenode and decompiled Node.js bytecode in Ghidra
[8] Decompiling Node.js in Ghidra
[9] Guide to P-code Injection: Changing the intermediate representation of code on the fly in Ghidra
[10] Creating a Ghidra processor module in SLEIGH using V8 bytecode as an example
[11] ghidra sleigh doc
[12] Revolutionizing Embedded Software
[13] Interpreter Implementation Choices
[15] Launching Ignition and TurboFan
[16] TurboFan
[17] Taming architecture complexity in V8 — the CodeStubAssembler
[18] Ignition: Jump-starting an Interpreter for V8
[19] Lazy deserialization
[20] snapshot:src
[21] Firing up the Ignition interpreter