基础姿势
静态分析相关结构与工具
在编译原理和软件工程中,有多种结构用于分析/表示:
-
AST (Abstract Syntax Tree, 抽象语法树):AST是一种用来表示源代码结构的树形表示法。它通过去除源代码中的冗余信息(如括号),并以树的形式展示程序的结构,使得程序结构更加清晰。AST通常由编译器或解释器生成,在语法分析阶段之后形成,很多解释器是直接解释它去执行的。它是进行后续编译步骤的基础,静态分析JS时也以它为主,可去astexplorer查看各语言的AST,里面也有JS的各种AST工具,本文使用的是Babel。
-
CFG (Control Flow Graph, 控制流图):控制流图是一种图形化表示方法,用于描述程序执行过程中可能采取的所有路径。每个节点代表一个基本块(即一段没有分支的连续指令序列,它的最后一条指令通常是跳转,这里不要理解偏了),边则表示了从一个基本块到另一个基本块的转移关系。控制流图是一个有向图,它是控制流分析的基础(如控制流扁平化恢复),AST可以很容易的生成CFG,下面将详细介绍对它的分析。
-
DFG (Data Flow Graph, 数据流图):数据流图展示了程序中数据如何流动以及在哪里被计算。它强调的是值是如何通过各种操作符传递的,而不是具体的控制流程。这在一些常量解混淆时很重要,例如字符串常量拼接/常量扩展等,但本文不会使用它,而是直接用模式匹配去做。
-
CPG (Code Property Graph, 代码属性图):代码属性图是一种多关系图模型,用于表示程序的结构和语义。它将控制流图、数据流图、抽象语法树等不同的程序表示方法整合到一个统一的图模型中。CPG 包含节点和边,节点代表程序中的各种元素(如变量、函数、语句等),边则表示这些元素之间的关系(如控制流、数据流、调用关系等)。它包含的信息特别多,所以是很适合做各种分析,不过本文不会涉及(其实俺不会😭)。可参考joern/codeql
babel操作简介
Babel 是一个 JavaScript 编译器,它本来是用来将用户使用最新的 JavaScript 语法编写代码转换为向后兼容的版本,以便在各种环境中运行的。但是在代码混淆和反混淆中也有大用,它的处理分三步:
- 解析(Parsing):将源代码解析成抽象语法树(AST),由
@babel/parser完成。 - 转换(Transformation):使用插件对 AST 进行遍历和修改。这些插件定义了如何将 AST 中的某些节点转换为其他形式,这也是我们做功的点。插件通常使用
@babel/traverse来遍历 AST,并使用@babel/types来创建或修改节点。 - 生成(Generation):经过转换后的 AST 被转换回 JavaScript 代码。这个过程由
@babel/generator完成。
在转换时,是通过遍历找到要处理的点,然后做处理。遍历算法可以自己实现,但通常都会用默认的,我们写插件会使用访问者模式:
traverse(ast, {
enter(path) {
if (path.isIdentifier({ name: 'foo' })) {
path.node.name = 'bar';
}
}
});
在正式介绍前,说明四个基本概念:
- Node: AST 中的基本单元,树的一个节点,表示代码中的一个特定元素。
- Path: 从根节点到某个特定节点的路径,包含了节点及其上下文信息,我们在修改时经常操作它,常见操作有两类,
path.stop/path.skip等用来控制遍历,path.replaceWith/path.replaceWithMultiple/path.remove等来替换删除,具体看文档咯。 - Statement :是 JavaScript 代码中的一个语句,在 AST 中通常是
Statement类型的节点,我们在匹配时会用t.isXXStatement去判断类型,在修改时又可能会自己去定义新的类型,(复杂的地方建议用template)。 - Scope:作用域定义函数和变量的可见性与生命周期,例如我们可以使用绑定等去找某个变量的声明与引用。
现在介绍下编写流程,在访问器模式下,需要写在何时处理,分两步:
- 当什么状态(enter/exit/WhileStatement/IfStatement)时处理,这只能筛选到作用域/语句级类型级
- 再次自己写代码细分要匹配哪种类型,此时有三种方法,自己用t.isXXStatement等写逻辑筛选/用matcher/用codemod/matchers写
大概就酱,具体看文档吧!
处理建议
- 同类型混淆只处理一种格式,多种格式先转换再处理,下面例子会提到。
- 对每个转换器写单测,测好各种边界情况,因为反混淆太复杂了,需要经常修改,容易改出BUG。
- 多写运行时断言,提前发现错误。
以某狸子为例分析
该目标部分场景使用的就是传统的混淆技术,很适合学习,下面以此函数为例:
function r(e, r, o) {
for (var a = 1; void 0 !== a;) { // 循环
var t, i, n = 7 & a >> 3
switch (7 & a) { // 外层switch
case 0:
// 内层条件
void (1 == n ? a = 2 : n < 1 ? (g = 1, a = 3) : 2 == n ? a = 4 : n > 2 && (s = 0, a = 5))
break
case 1:
var h = 0, s = r
a = s ? 5 : 24
break
case 2:
return h
case 3:
var d = g
a = (F = (z = (F = !W) * F) > -159) ? 16 : 7; // 虚假控制流
break
case 4:
var c
a = v < l ? 6 : 8
break
case 5:
var v = s, l = e.length, g = o
a = g ? 3 : 0
break
case 6:
var C, f
h = 0 | 31 * h, h += e.charCodeAt(v), v += d, a = 16
break
case 7:
h = (He = K = 0) ? 9 : 8; // 虚假控制流2 (演示用,实际也是死代码,不会有case7)
break
}
}
}
if转switch
首先void()是传统技艺,直接去除,剩下的是连着的三目表达式,它需要再继续转为if-else便于分析,转换完分析会发现它其实是个switch-case转的if,而内层switch的状态变量和外层switch的状态变量及循环是存在运算关系的:n = 7 & a >> 3与7 & a与a,请务必观察它们,弄清楚关系,这会影响接下来怎么实现代码。现在先看怎么把if转回switch,switch的case只能接受常量(如case 1:),而if可以做运算(如if(n<1)),故反向转换时更加复杂,有两种思路:
-
思路1:根据约束计算:对于
if(n==1)是能直接转的,而对于if(n<1)则需要更多约束转换为if(n==?)的形式,仔细分析上面的式子可知n>=0且是整数,其它情况也可以如此静态约束求出解(参考符号执行约束求解)。 -
思路2:模拟执行:直接掩盖住业务逻辑代码,而保留混淆的控制语句,用数字为原有逻辑编号并写在要模拟执行的代码里,执行一遍就能找到对应关系了,如:

对于思路2,核心是识别出哪些是混淆的控制逻辑,哪些是原始业务逻辑,但只要把形式转换标准,那么根据内层switch的控制变量即可精准识别。
注:
请思考这一步及之后步骤存在的必要性,其实,根据后面处理方式的不同,它可以是不必要的!
不要直接执行,在沙盒里跑,安全第一!
多层嵌套switch转一层
转换回switch后,现在就是嵌套的switch了,上一步已经提到,每层switch的状态变量是存在联系的,这个例子是两层嵌套,实际还存在更多层,但每层的状态变量都是由最外层循环使用的变量做固定运算得来的,即每一层的是循环变量的某几位,如n = 7 & a >> 3与7 & a分别是高3位与低三位,因此是可以统一状态变量,从而将多层嵌套转换为一层的,而要做的唯一就是找到新的状态变量值(如此处的n==1需转换为a==8)了,解决思路同样有两种:
-
思路1: 直接计算:都是按位的关系了,直接找到每一层它是原始的哪几位,以及每一层它外层的值,或起来就得到统一后的值了
-
思路2: 模拟执行,思路同上
这里采用思路1,展开说下,它需要递归的处理,从外层到内层,在每一层记录当前状态变量和实际状态变量之间的映射关系(在哪几位),以及它的上层是什么:
// 状态值 = baseState | (caseValue << shift)
const maskBits = currentStateVar.mask === -1
? 0 // 对于纯位移操作,不应用掩码
: currentStateVar.mask << currentStateVar.shift
const clearState = baseState & ~maskBits
const stateValue = clearState | ((caseValue & (currentStateVar.mask === -1 ? -1 : currentStateVar.mask)) << currentStateVar.shift)
例如:
for (var Sc = 82624; Sc !== undefined;) { // Sc为真实状态变量,下面全是要算它
var jc = Sc >> 6;
var xc = jc & 63;
var Ec = jc >> 6 & 63;
switch (Sc & 63) { // 第一层是Sc[0:5]位
case 1:
switch (xc) { // 第二层是Sc[6:11]位
case 2:
switch (Ec) { // 第三层是Sc[12:17]位
case 3:
... // 故此Sc实际值是 (3<<12)|(2<<6)|1 == 12417
虚假控制流消除
如上(F = (z = (F = !W) * F) > -159)无论W何值,!W必为1或0,它的平方亦是如此,故定大于负数,即条件永真。而(He = K = 0) ? 9 : 8很明显条件永假。
-
思路1:静态分析:它有两个挑战,识别出它的模式以及计算真实分支。识别模式单从肉眼其实工作量蛮大,方法就是找三目运算,给它们归类,再自己挨个看或者喂给AI分析,另外可以在后续控制流分析去找异常结构。当找到虚假分支分叉点时,下一步就是分辨出哪个是真的。
-
思路2:插桩追踪,即插入桩代码后令其在正常环境中运行,收集其执行到的所有分支,没执行到的再手动检查是否是死代码。这里隐含的坑就是目标代码可能会检测代码完整性并跳转到虚假分支。
这里得仔细说下思路1的第二步,像例子里这两种情况是很简单的,单一语句就能辨别,而在实际的代码中它可能很复杂,即它的伪条件会是多条语句计算,并分布在多个case块里,因此需要先做简单的控制流分析,再将其完整提取出来。而要提取又是一个问题,比如哪些代码该提,这得分析它的特征,例如下面的式子,它的特征就是F/H/V/U/W/G都是在某位置外层一起定义的,那么先找到这几个变量及其定义位置,之后检查每条语句涉及的标识符是否只包含这几个变量(需确认是同一个变量,防止内部作用域定义了同名变量导致提错),找完后模拟执行即可:
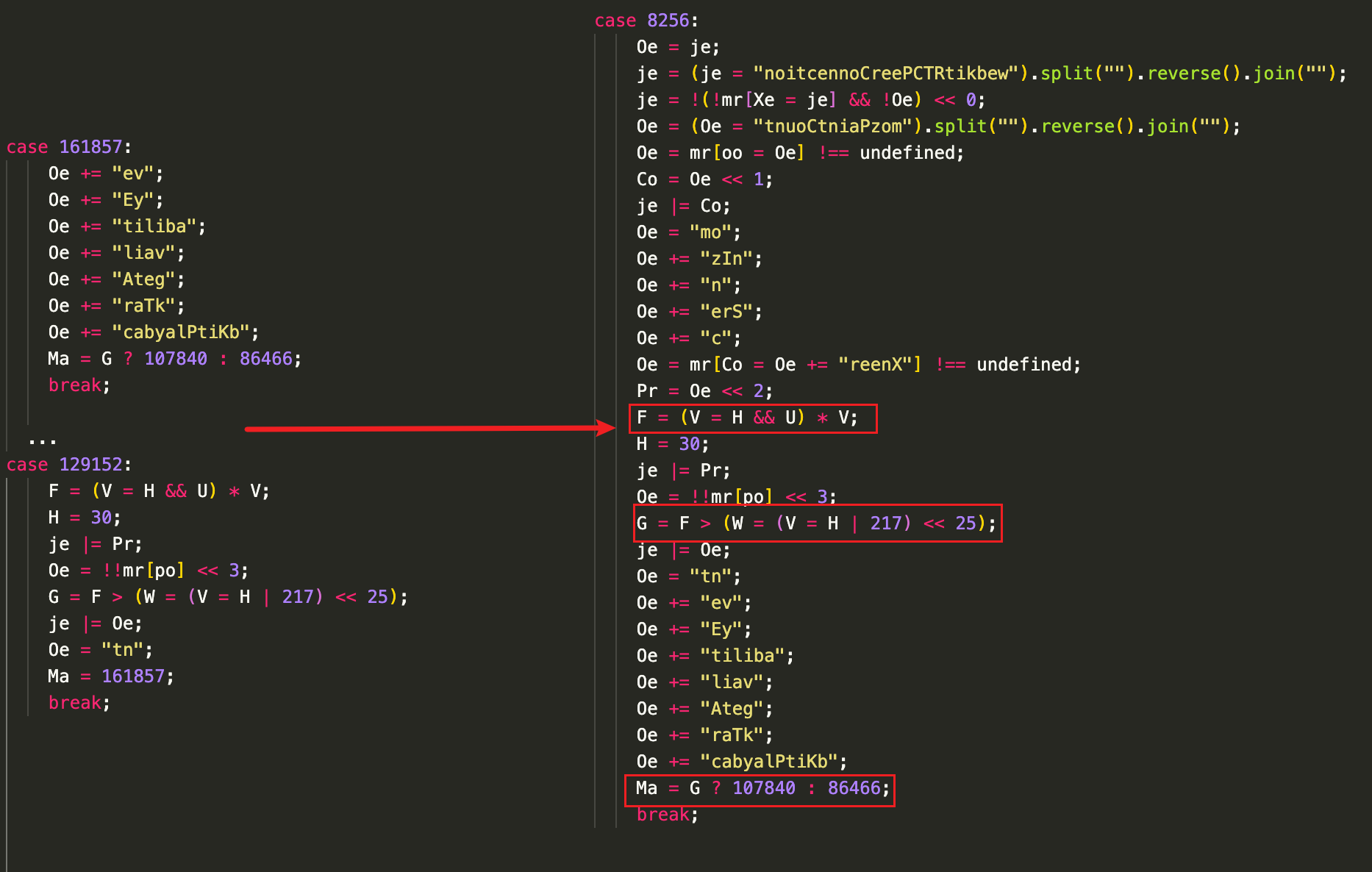
注:对于思路2,不一定需要去修改代码,可利用chrome的日志点功能来实现,但是这种方式只适合小的函数,因为log性能损耗很大,最好还是直接改,先用字典存每个case实际可达后继。
控制流平坦化恢复 (高级结构恢复)
AST转CFG
生成控制流的方法不多说,需要提的是建议加上Entry/Exit这两个虚拟节点,之后处理起来方便。在当前的输入下,CFG只含有如下类型节点:
export type CFGNodeType =
| 'entry'
| 'exit'
| 'condition' // 含跳转跳转的case块,由于前文的处理,它一定会是有两个后继的跳转 如var xx=3; r = a > 0 ? 2 : 6;
| 'case' // 表示不含条件跳转的case块 a++; r = 3;
生成控制流后,它只包含低级结构,即顺序和条件跳转,如果在C语言里是可以通过goto来生成勉强能看的源码的,但实际是需要恢复更高级的结构。
JS控制流结构及其控制流图
顺序结构(Sequential Execution)
从上到下按顺序执行,没有分支或循环。无需多言。
条件结构(Conditional Branching)
在关键词上,存在if/switch-case/?:三类,其中三目运算和switch-case显然可以用if表示,所以为了简便此处不恢复这两类结构,它可在后续由单独的插件恢复,此处只关注if语句,而if又分为两种:if-then/if-then-else。(if-else反转条件即为if-then,也可将其视为含空语句的if-then-else,不单独处理)总的来说它很简单,控制流图如下:
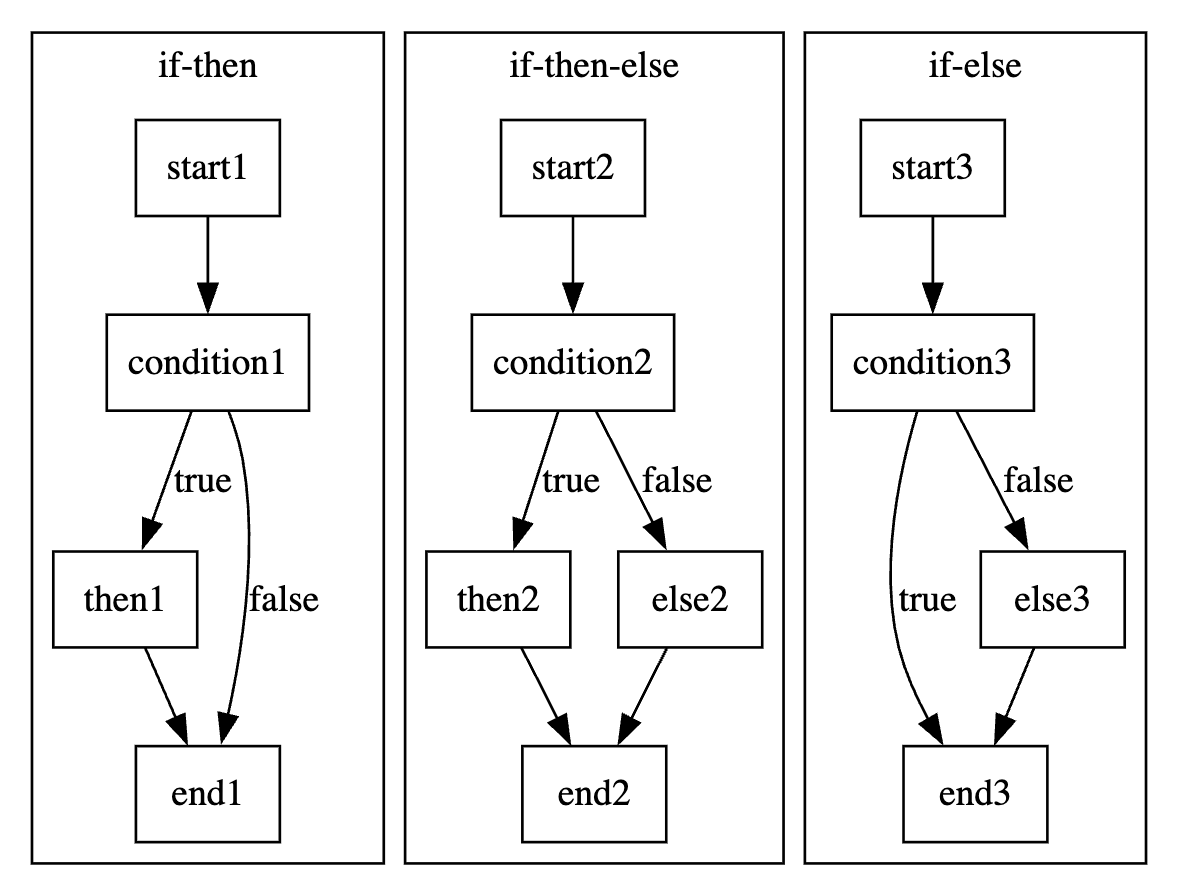
关键就是确认是否是if块,以及找到它的合并节点,之后就能收集then/else分支了。
循环结构
在关键词上,含while/do-while/for三类,for是while的语法糖先忽略,不过按形式还有种无限循环 (如while(true)/for(;;)但其实也可以转换为do-while)类型。对于循环,先说下几种关键节点:
-
Header:循环的入口节点,对于while语句,就是while条件那个节点,对于do-while就是循环体内的第一个节点。
-
Latch:该节点有条边指向Header节点(回边)从而形成一个循环结构。
-
Follow:循环结束后控制流首先到达的节点。
-
While-Condition:含判断条件的节点,对于while就是头节点,对于do-while就是最后一个节点,它一条边指向循环体内,一条边指向Follow。
在循环结构中,还需要再关注三类跳转语句:continue/break/return,它们是跳转语句会影响控制流程,特别是它们能带标签导致有多个出口:
outerLoop: for (let i = 0; i < 3; i++) {
for (let j = 0; j < 3; j++) {
if (i === 1 && j === 1) {
break outerLoop; // 跳出outerLoop标签对应的循环
}
console.log(`i=${i}, j=${j}`);
}
}
console.log("循环结束");
下面会画出几种不含外层跳转的图,请仔细查看规律哦~
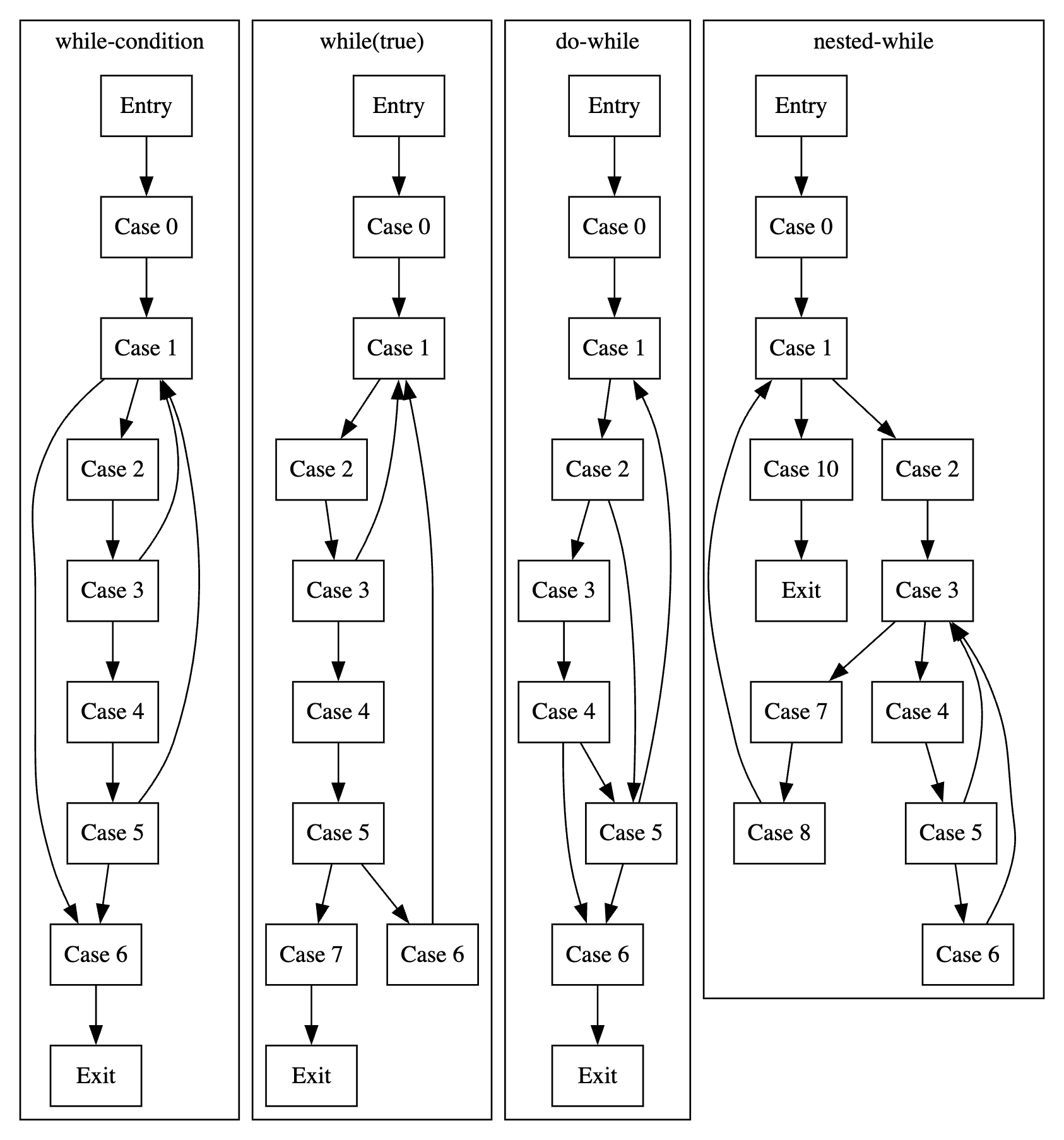
请对每一个类型,找出上面提到的几个节点,再找出可能的continue/break节点!这里只简单说下前三个:
- while(condition):header和while-condition节点都是case1,follow是case6,case5不经while-condition节点就指到case6所以含break,case3和case5能直接指到while-condition所以含continue。(continue很特殊,可以转换忽略,比如case5是循环体内最后一个节点,显然是不需要continue就能回到while-condition的,故可忽略continue)
- do-while:header是case1,while-condition是case5,follow是case6,case4不经while-condition节点就指到case6所以含break,case2和case4能直接指到while-condition所以含continue。
- while(true):header是case1,case1可以看作是while-condition,follow是case7,case5直接到case7所以含break,case3直接到while-condition所以含continue。(它很特殊,下面会说到处理办法)
注:
for-in/for-of虽然是js里的关键词,但for-of其实是语法糖不必特殊处理,而for-in语法很复杂通常混淆不会处理它。- 其它结构,如异步,异常暂时没发现,异步其实是生成器+Promise,而异常需要单独的handler表,在狸子中暂未发现该结构。
反编译技术
上面主要是介绍了三种类型的CFG结构特征及识别方法,下面就是使用结构识别技术做恢复,它采用规约的思想,将一个结构化(可规约)的区域用一个简单节点代替,将复杂的结构转换为简单的结构,重复该步骤最终能将CFG规约成一个点,即完成了识别,再根据规约过程识别到的高级结构信息修改AST就能完成恢复咯!
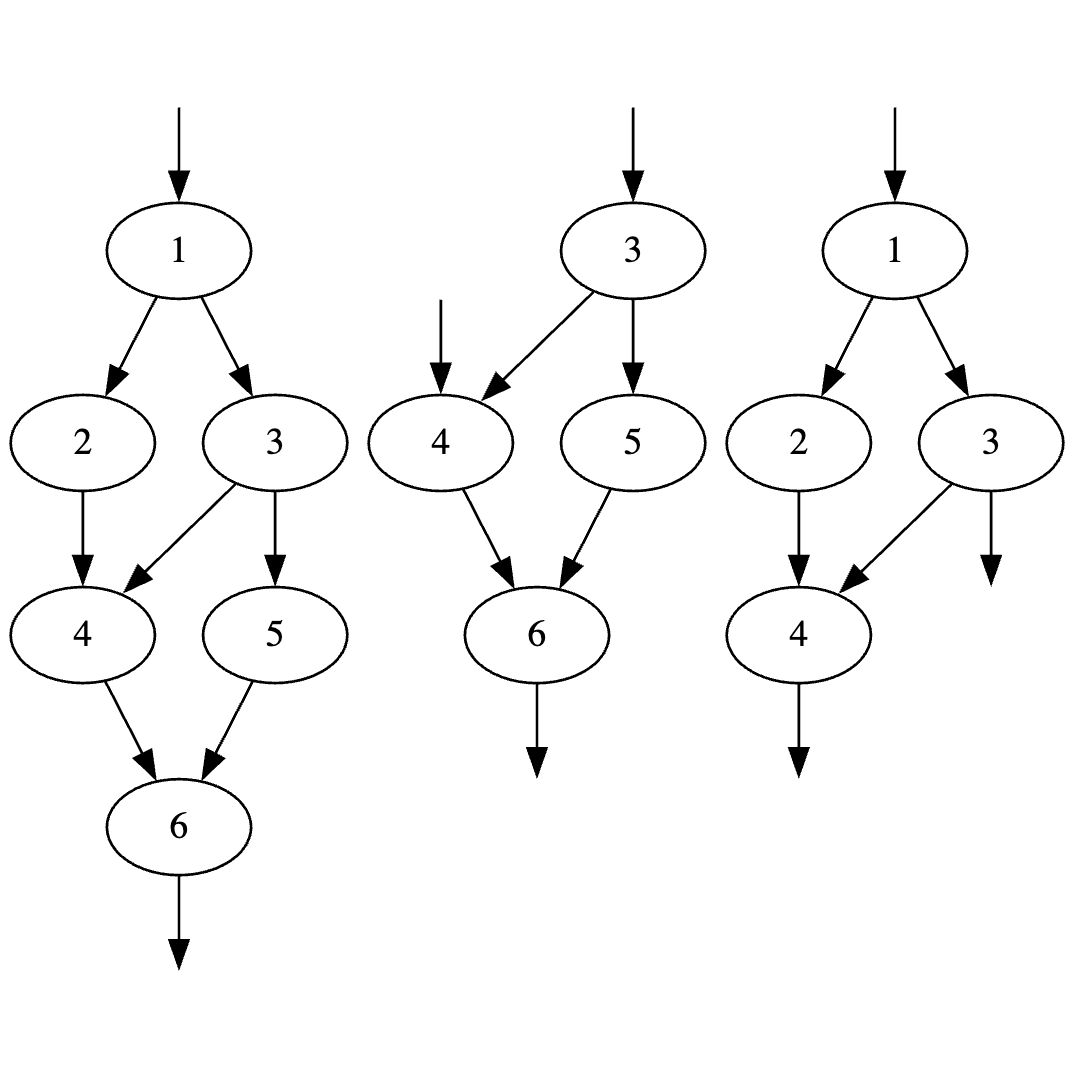
再此,需要说下什么是结构化的区域,[2]将只有一个入口和一个出口的区域视作结构化区域,上面提到的除了break/continue到外层循环外,目前都还是符合这种特征,下面贴一个书里提到的,不满足该条件的图,它们被分开后会有多个入口或出口,对于这种类型可以用做标记或者复制节点去改成可规约结构:
再提一个,CFG是有向图,下面都是使用DFS(深度优先搜索)去遍历它的,只是基于它做了更多操作,另外提一下在DFS是也存在类似树的前/后序遍历,这里使用后序。
顺序结构识别
只需遍历每个节点,如果它们连成一条边就行,具体的说入口节点的前驱个数要大于等于1(不合并虚拟entry节点),之后每个节点的前驱和后继都必须是1:
const hasProcessed = new Set<string>()
this.cfg.traverseTopDown((nodeId, node, _) => {
const sequenceNodes = new Array<string>()
let currentNode = node
while (currentNode.successors.length >= 1) {
if (sequenceNodes.length > 0 && currentNode.predecessors.length > 1) { // 仅允许第一个节点的前驱有多个
break
}
if (hasProcessed.has(currentNode.id)) break
// if (this.loopInfos.has(currentNode.id)) { // 似乎不需要
// break
// }
sequenceNodes.push(currentNode.id)
hasProcessed.add(currentNode.id) // 这里即使未使用也没问题,因为它一定不能用咯
if (currentNode.successors.length > 1) { // 仅允许最后一个节点的后继有多个
break
}
currentNode = this.cfg.getNode(currentNode.successors[0])!
}
if (sequenceNodes.length === 0) {
return
}
else if (sequenceNodes.length === 1) {
hasProcessed.delete(sequenceNodes[0])
return
}
// 创建结构信息
const lastNode = this.cfg.getNode(sequenceNodes.at(-1)!)!
const structureInfo: ReginInfo = {
type: 'sequence',
entryNodeId: sequenceNodes[0],
lastNodesId: [lastNode.id],
allNodes: new Set(sequenceNodes),
info: { sequenceNodes },
}
this.markedStructures.set(sequenceNodes[0], structureInfo)
})
这里需要先循环多次把能规约的全规约咯。
条件结构识别
条件结构其实分两种:1. 不带跳转语句的条件语句 和 2. 带跳转语句的条件语句。这里先只处理不带跳转语句的条件语句,在之前的阶段,所有条件分支都被处理成了有且只有两个后继的节点(统一格式),AST转CFG时它们被表示为condition类型,实际上它们可能是条件块的头,也可能是循环的判别语句,但是它们之间存在区别,条件块里语句都是向下的,而循环会有向上的回边,理清了此,就可以识别if块了。它有两种方法,第一种方法很简单,是YC大哥教的,可能也是鲸书里的方法,就是先规约能规约的,再匹配两种模式:
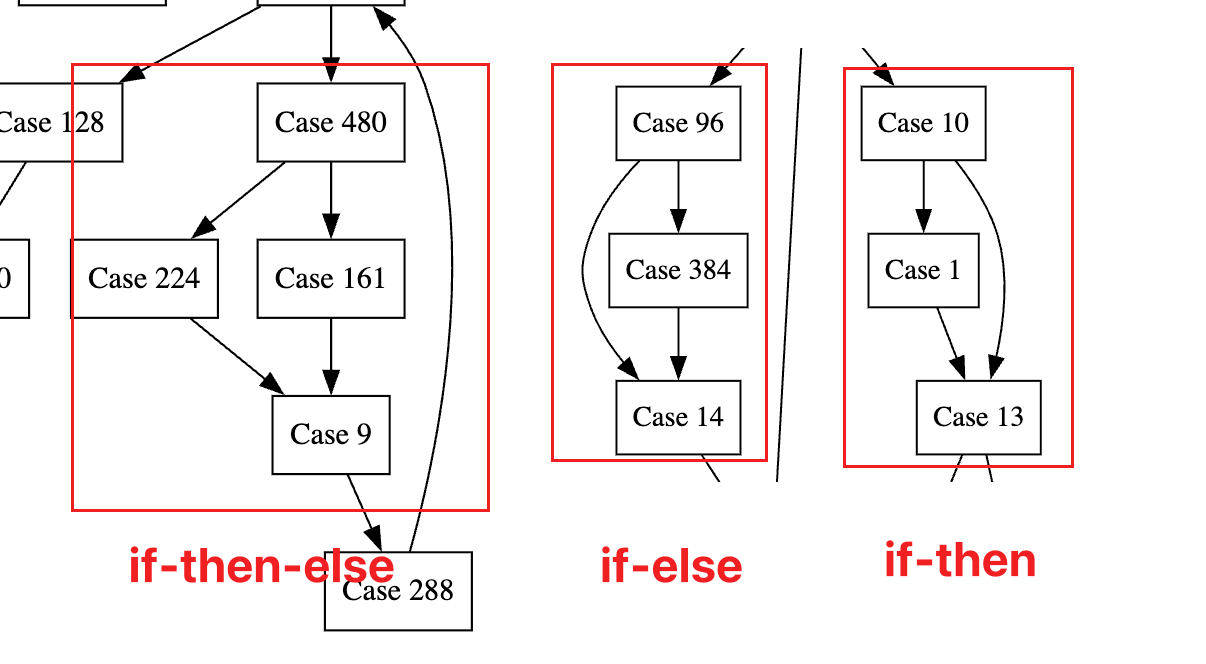
如图,规约完后,if块只会涉及3或4个节点,如果condition的两个后继的后继相同则是if-then-else,如果一个后继是另一个后继的后继则是if-then/if-else,直接匹配这种模式即可。
而另一种方法要复杂不少,它不需要先规约顺序区域,那就是在复杂的图上做识别,这需要引入一个关键概念,支配节点(dominator node,也叫必经节点),即到某节点必须经过哪些节点,则那些节点就其支配节点,最近的叫直接支配节点,可以对CFG从Entry开始遍历算出一颗树-支配树,利用它就能快速知道哪些是条件节点了,不过更重要的是如果从Exit开始反向算就能得到一颗后支配树,利用它可以快速确定if的合并点。而这两颗树必须用高效的算法构成,如Lengauer-Tarjan,原始算法在这个场景时间复杂度太高了是算不出来的!
好了,有了后支配树,就能判断当前的condition块是否是能规约的if块了,方法就是找合并点,以及then和else分支到合并点这个路径是否还有condition结构,如果有则无法规约,否则就找到一个可规约的if块了:
this.cfg.traverseTopDown((nodeId, node) => {
if (node.type !== 'condition') return
const [branchA, branchB] = node.successors
// 检查分支是否是回边,如果是回边则跳过(这不是普通的if语句)
if (isBackEdge(nodeId, branchA, dominatorTree) || isBackEdge(nodeId, branchB, dominatorTree)) {
logger.debug(`节点 ${nodeId} 的分支包含回边,跳过(可能是循环结构)`)
return
}
// 使用支配树方法寻找合并点
const mergePoint = findMergeNodeUsingDominatorTree(this.cfg, branchA, branchB, postDomTree)
if (!mergePoint) {
logger.warn(`支配树中没找到合并点,跳过节点 ${nodeId} 或许是在循环里往前跳`)
return
}
// 收集分支节点
const thenNodes = this.collectBranchNodes(branchA, mergePoint)
if (thenNodes === null) {
logger.debug(`节点 ${nodeId} 的分支包含复杂结构,跳过标记`)
return
}
const elseNodes = this.collectBranchNodes(branchB, mergePoint)
// 如果收集分支节点时发现复杂结构,跳过该if-else结构
if (elseNodes === null) {
logger.debug(`节点 ${nodeId} 的分支包含复杂结构,跳过标记`)
return
}
// 判断结构类型
let structureType: 'if-then' | 'if-then-else'
if (branchA === mergePoint || branchB === mergePoint) {
structureType = 'if-then'
}
else {
structureType = 'if-else'
}
// 创建结构信息
const structureInfo: ReginInfo = {
type: structureType,
entryNodeId: nodeId,
succNodeId: mergePoint,
allNodes: new Set([nodeId, ...thenNodes, ...elseNodes]),
info: {
ifNode: nodeId,
thenBranch: Array.from(thenNodes),
elseBranch: Array.from(elseNodes),
},
}
this.markedStructures.set(nodeId, structureInfo)
})
循环结构识别
循环估计用YC大哥的思路也会很简单,没细想。这里还是用复杂的吧,循环本身可通过括号定理(Parenthsis Theory)识别,这里依然选用高效的Tarjan算法,它能高效的识别SCCs(强连通分量),需要注意识别出所有的嵌套循环,但要剔除非循环结构,如循环里存在continue时会构成更小的环,但它们使用同一个循环头,所以属于同一个循环!识别出循环后,需要先将其全局存储并打标签,因为JS存在continue/break label语法,它可能从内层循环跳老远!
接下来,就可以从内层循环开始遍历,先识别带跳转语句的条件语句,因为这种语句只存在于循环内,且会向回跳,所以需要在这里面识别,上面已经提到它的特征了,如果它的分支后继序列都是非condition结构,且指向follow节点,则分支含break,如果指向while-condition节点则含continue,如果还有其它的出边,继续看它是否指向外层循环的这两点,是就continue/break到对应标签,都不是再看是不是到Exit节点,表示return,如果都不是则是无法规约的结构!
这里只识别while和do-while,上面提到循环头后继有两个的就是while,只有一个后继的就是do-while,但仔细观察while(true)是并不符合两个的特征,因为它的header只有一个后继,但是把它当做do-while时,while-condition应该循环体内分支应该直接指向header,所以也不满足后者,一个处理办法就是给CFG增加一条假边,由于while(true)所以它的false边永远不会执行,但是此时就可以将其当做while(condition)规约了,如下:
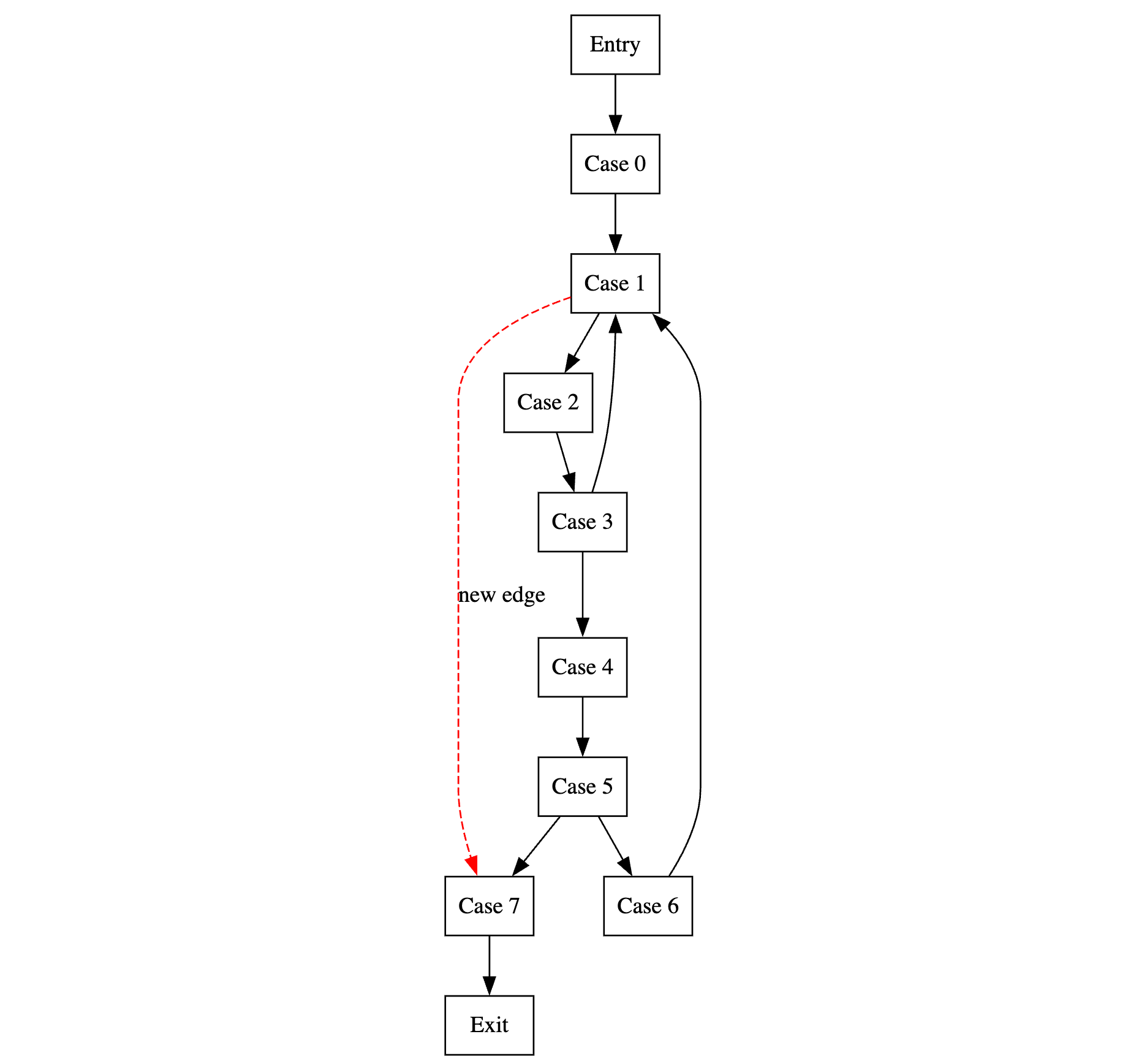
识别完它后,就看当前的循环是否可规约了,可以则Do It!
说一下continue/break/return分支怎么处理,它本是循环内的节点连到循环外(continue不带标签除外,它直接连到循环的条件语句所以可以不处理),对于其它情况可以先插入对应的AST STMT,然后修改CFG的节点关系,将其后继指向循环条件处,它就变成可规约结构了。
CFG转AST
在上一步中,已经对CFG做规约了,此时直接从入口遍历CFG只会存在三个节点:Entry,Sequence,Exit。其中Sequence是区域类型,而且根据我们的逻辑它是特殊的区域类型,我们直接展开它即可。在这个过程中需要递归处理区域:
export type CFGNodeType =
| 'entry'
| 'exit'
| 'case'
| 'break'
| 'continue'
| 'return'
| 'sequence' // 后面这5种是区域类型,需要递归处理
| 'if-then'
| 'if-then-else'
| 'while'
| 'do-while'
在处理区域时有个注意点,不要去处理它们的后继,因为每种类型都被规约成一个点了,顾只能处理其区域内的部分:
function cfgToAst(cfg: CFG): t.Statement[] {
// 递归处理CFG节点
const processNode = (nodeId: string, endNodeId?: string | null): Statement[] => {
const node = cfg.getNode(nodeId)
if (!node || node.hidden) {
return []
}
const statements: t.Statement[] = []
// 根据节点类型和分析结果生成对应的AST
switch (node.type) {
case 'entry':// 入口节点,处理其后继
assert(node.successors.length === 1, `入口节点 ${nodeId} 应该只有一个后继`)
statements.push(...processNode(node.successors[0], endNodeId))
break
case 'exit':
// 出口节点,不需要处理
break
// 处理结构化区域 - 利用保存的结构信息
case 'sequence':
// 顺序区域:利用结构信息恢复原始语句
statements.push(...processSequenceRegion(node))
assert(node.successors.length === 1, `顺序区域节点 ${node.id} 应该只有一个后继`)
// 处理后继节点
statements.push(...processNode(node.successors[0], endNodeId))
break
default:
throw new Error(`不应该存在未归类的节点类型 ${node.type}!`)
}
return statements
}
const processSequenceRegion = (node: CFGNode): t.Statement[] => {
assert(node.region, `节点 ${node.id} 缺少区域信息`)
// 找到入口节点
return collectBranchStatements((node.region.info as SequenceReginInfo).sequenceNodes)
}
// 处理 if-then 区域
const processIfThenRegion = (node: CFGNode): t.Statement[] => {
const statements: t.Statement[] = []
const structureInfo = node.region! as IfStructureInfo
assert(structureInfo, `if-then 区域节点 ${node.id} 缺少结构信息`)
// 获取条件表达式
const entryNode = cfg.getNode(structureInfo.entryNodeId)
assert(entryNode.astNode, `if-then 区域入口节点 ${structureInfo.entryNodeId} 缺少条件表达式`)
if (entryNode?.originalStatements) {
statements.push(...entryNode.originalStatements)
}
// 收集 then 分支的语句
const thenStatements = collectBranchStatements(structureInfo.info?.thenBranch)
const ifStatement = t.ifStatement(
entryNode.astNode as t.Expression,
t.blockStatement(thenStatements),
)
statements.push(ifStatement)
return statements
}
// 处理 if-else 区域
const processIfElseRegion = (node: CFGNode): t.Statement[] => {
const statements: t.Statement[] = []
const structureInfo = node.region! as IfStructureInfo
if (!structureInfo) {
logger.warn(`if-else 区域节点 ${node.id} 缺少结构信息`)
return []
}
// 获取条件表达式
const entryNode = cfg.getNode(structureInfo.entryNodeId)
if (!entryNode?.astNode) {
logger.warn(`if-else 区域入口节点 ${structureInfo.entryNodeId} 缺少条件表达式`)
return []
}
if (entryNode?.originalStatements) {
statements.push(...entryNode.originalStatements)
}
// 收集 then 和 else 分支的语句
const thenStatements = collectBranchStatements(structureInfo.info?.thenBranch)
const elseStatements = collectBranchStatements(structureInfo.info?.elseBranch)
const ifStatement = t.ifStatement(
entryNode.astNode as t.Expression,
t.blockStatement(thenStatements),
elseStatements.length > 0 ? t.blockStatement(elseStatements) : null,
)
statements.push(ifStatement)
return statements
}
// 处理 while 循环区域
const processWhileRegion = (node: CFGNode): t.Statement[] => {
const statements: t.Statement[] = []
const structureInfo = node.region! as LoopStructureInfo
assert(structureInfo !== undefined, `while 区域节点 ${node.id} 缺少结构信息`)
// 获取循环头条件表达式
const headerNode = cfg.getNode(structureInfo.info.loopHeader)
if (headerNode?.originalStatements) {
statements.push(...headerNode.originalStatements)
}
assert(headerNode.astNode !== undefined, `while 区域循环头节点 ${structureInfo.info.loopHeader} 缺少条件表达式`)
// 收集循环体语句
const bodyStatements = collectBranchStatements(structureInfo.info.loopBody, structureInfo.entryNodeId)
const whileStatement = t.whileStatement(
headerNode.astNode as t.Expression,
t.blockStatement(bodyStatements),
)
statements.push(whileStatement)
return statements
}
// 处理 do-while 循环区域
const processDoWhileRegion = (node: CFGNode): t.Statement[] => {
const statements: t.Statement[] = []
const structureInfo = node.region! as LoopStructureInfo
if (!structureInfo) {
logger.warn(`do-while 区域节点 ${node.id} 缺少结构信息`)
return []
}
// 收集循环体语句(排除条件节点)
const bodyStatements = collectBranchStatements(structureInfo.info.loopBody)
const conditionNode = cfg.getNode(structureInfo.info.conditionNode)
if (conditionNode?.originalStatements) {
statements.push(...conditionNode.originalStatements)
}
const doWhileStatement = t.doWhileStatement(
conditionNode?.astNode as t.Expression,
t.blockStatement(bodyStatements),
)
statements.push(doWhileStatement)
return statements
}
// 收集分支语句的辅助函数 - 基于隐藏节点
const collectBranchStatements = (nodeIds?: string[], entryNodeId?: string): t.Statement[] => {
const statements: t.Statement[] = []
if (!nodeIds) return statements
// 按照拓扑顺序收集语句
const collectFromNode = (nodeId: string): void => {
const hiddenNode = cfg.getNode(nodeId)
assert(hiddenNode.hidden, `节点 ${nodeId} 不是隐藏节点`)
// 根据节点类型处理不同的语句生成
switch (hiddenNode.type) {
case 'case':
case 'break':
case 'continue':
case 'return':
// 普通语句节点,添加原始语句
if (hiddenNode.originalStatements) {
statements.push(...hiddenNode.originalStatements)
}
break
case 'condition':
throw new Error('不应该出现低级条件类型')
case 'sequence':
// 顺序区域,递归处理区域内的节点
for (const regionNodeId of (hiddenNode.region!.info as SequenceReginInfo).sequenceNodes) {
collectFromNode(regionNodeId)
}
return
case 'if-then':
case 'if-else':
// if区域,使用区域的结构信息生成if语句
{
const structureInfo = hiddenNode.region! as IfStructureInfo
const entryNode = cfg.getNode(structureInfo.entryNodeId)
assert(entryNode.astNode && t.isExpression(entryNode.astNode), `入口节点必须含表达式哦~`)
const thenStatements = collectBranchStatements(structureInfo.info.thenBranch)
const elseStatements = collectBranchStatements(structureInfo.info.elseBranch)
if (entryNode?.originalStatements) {
statements.push(...entryNode.originalStatements)
}
const ifStatement = t.ifStatement(
entryNode.astNode,
t.blockStatement(thenStatements),
elseStatements.length > 0 ? t.blockStatement(elseStatements) : null,
)
statements.push(ifStatement)
return
}
break
case 'while':
case 'do-while':
// 循环区域,使用区域的结构信息生成循环语句
{
const structureInfo = hiddenNode.region! as LoopStructureInfo
const bodyStatements = collectBranchStatements(structureInfo.info.loopBody.filter(id => id !== structureInfo.info.conditionNode))
let loopStatement: t.Statement
const conditionNode = cfg.getNode(structureInfo.info.conditionNode)
if (hiddenNode.type === 'while') {
loopStatement = t.whileStatement(<Expression>conditionNode.astNode!, t.blockStatement(bodyStatements))
}
else if (hiddenNode.type === 'do-while') {
if (conditionNode.originalStatements) {
loopStatement = t.doWhileStatement(<Expression>conditionNode.astNode!, t.blockStatement([...bodyStatements, ...conditionNode.originalStatements]))
}
else {
loopStatement = t.doWhileStatement(<Expression>conditionNode.astNode!, t.blockStatement(bodyStatements))
}
}
else { // for
loopStatement = t.forStatement(null, <Expression>conditionNode.astNode!, null, t.blockStatement(bodyStatements))
}
if (hiddenNode.type === 'while' || hiddenNode.type === 'for') {
if (conditionNode?.originalStatements) {
statements.push(...conditionNode.originalStatements)
}
}
statements.push(loopStatement)
return
}
break
default:
throw new Error(`不支持的节点类型:${hiddenNode.type}`)
}
}
// 找到分支的入口节点并开始收集
for (const nodeId of nodeIds) {
const hiddenNode = cfg.getNode(nodeId)
assert(hiddenNode.hidden, `区域里的节点应该都是隐藏状态的`)
// 检查是否是入口节点(没有来自分支内部的前驱)
if (nodeId !== entryNodeId) {
collectFromNode(nodeId)
}
}
return statements
}
// 从入口节点开始处理
return processNode(cfg.entryNode)
}
之后再将其替换回去,除掉多余的while-switch即可。
字符串恢复
它的字符串有三类混淆方式,下面依次说明处理办法
字符串连接
如下,这类据我YC大哥说有数据流图就好做了,俺没有,那就用模式匹配硬搞。实际还有多种形式,需要先使用代码将其转换为如下形式,将其称作标准形式吧,再处理:
var na;
var a = "Re"; // 声明处被初始化为字符串常量
a += "spo";
a += "nse";
na = "n"; // 被赋值为字符串常量
na += "oit";
na += "a";
var b = "js";
b += "on";
处理方法就是从上往下看每个作用域的变量声明/赋值,当找到一个变量被初始化/赋值字符串常量时,就继续往下找,看有没有a += '字符串常量'的语句,有就直接计算出值,它的结束条件是:1.作用域结束了 2. 变量被使用了 3. 出现了子块等复杂语句,特别是第三点由于太复杂还是不要解析为好。
字符串反转
字符串反转很简单,它只有一种模式xx.split("").reverse().join(""),所以很容易匹配出来:
function isReverse(path: NodePath<t.CallExpression>) {
// 检查是否是 .join("") 调用
if (!t.isMemberExpression(path.node.callee)
|| !t.isIdentifier(path.node.callee.property, { name: 'join' })
|| path.node.arguments.length !== 1
|| !t.isStringLiteral(path.node.arguments[0], { value: '' })) {
return
}
const joinCall = path.node
const joinCallee = joinCall.callee as t.MemberExpression
const reverseCall = joinCallee.object
// 确保 reverseCall 是 .reverse() 方法调用
if (!t.isCallExpression(reverseCall)
|| !t.isMemberExpression(reverseCall.callee)
|| !t.isIdentifier(reverseCall.callee.property, { name: 'reverse' })) {
return
}
const reverseCallee = reverseCall.callee as t.MemberExpression
const splitCall = reverseCallee.object
// 确保 splitCall 是 .split("") 方法调用
if (!t.isCallExpression(splitCall)
|| !t.isMemberExpression(splitCall.callee)
|| !t.isIdentifier(splitCall.callee.property, { name: 'split' })
|| splitCall.arguments.length !== 1
|| !t.isStringLiteral(splitCall.arguments[0], { value: '' })) {
return
}
const splitCallee = splitCall.callee as t.MemberExpression
// 获取原始字符串表达式
return splitCallee.object
}
难的是xx,它最好是字符串常量,但实际可能会是很多其它类型,比如变量或表达式,故此处需要将其转化为标准形式,将表达式计算到字符串常量级别,再处理!
字符串解码
根据[3]说它的字符串编码有两种形式,一种是用全局栈传参和在特定函数里计算,一种是简单的循环处理,暂时只遇到后种:
var C = "ÆÍÒÈ";
var f = "";
var m = 0;
while (m < C.length) {
var v = C.charCodeAt(m) - 100;
f += String.fromCharCode(v);
m++;
}
这里它有for和while两种形式的循环,而循环体内的计算逻辑也分多种,如^/+/-等,识别并模拟执行即可,在处理它时尤其要注意统一形式,例如先全部转换为while再处理。
注:后序可尝试复现下JSHint试试,看论文效果挺好!
代码分割
待续...
标识符恢复
标识符包含函数名/常量/变量名等,对它们的处理本身是不可逆的,之前更多是根据逆向人员的经验/推测/分析恢复,而现在有了LLM,当代码被分割为合理大小的块后,就可以使用它去恢复了。这块可参考humanify blog code 的思路!
分析结果
简单描述下算法分析结果,它会使用一个全局的状态数组存放各种信息,如事件、计数器、随机值、时间戳、设备指纹、异常检测等信息,并在之后打包,算法大概如下,不同的参数会有细微差别:
prefix+custom_base64(
total_check_sum,
nonce_key,
# part1
part1_chcksum, part1_size,
encode1(data,key),
# part2
part2_chcksum, part2_size,
encode2(data,key),
# part3, 4, 5...
# ...
)
这里的校验和不同的参数算法会有差别,同样的参数每一部分校验和的常数也会有差别,每一部分是多个状态数组被编码后的字节数组,编码方式有变长数字、带长度的字符串和固定长度编码,之后会有encodeN函数再对其编码,每个函数含4个简单的算法,如移位、异或等,每两字节选一个算法编码,每个encodeN的算法都不相同,如有4部分就会有16种算法去编码,最后再由自定义的base64算法加上固定前缀(版本相关)来生成最终结果。
参考
[1] 静态程序分析 -- 南京大学甜品学院青年厨师
[2] 编译与反编译技术 -- 庞建明 陶红伟 刘晓楠 岳峰
[3] Design and implementation of Bulldozer A decompiler for JavaScript “binaries” -- @ceres-c and @MrMoDDoM
[4] 还原某里226控制流混淆的思路 -- sergiojune
[5] JSHint: Revealing API Usage to Improve Detection of Malicious JavaScript -- {ssarker,krschulz,anahape,anupam.das,akaprav}@ncsu.edu